Mongodb 学习笔记

1 安装
1.1 win10 安装
在 windows 下安装可以参考这篇文章mongodb-window-install。
1.1.1 小坑
我使用的是 windows 10 企业版,在安装时出现了个问题,如下:
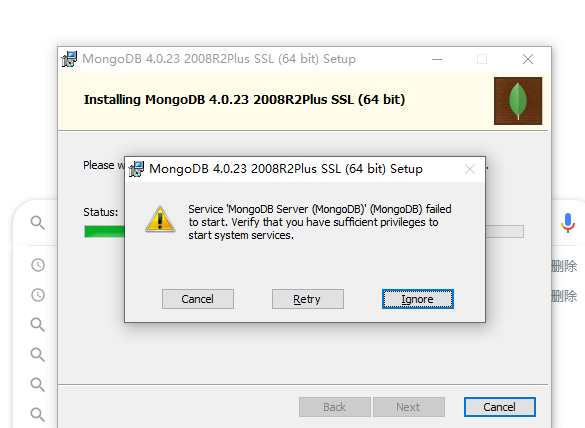
我是在网上找了大半天没有找到解决的办法,都是写文章作者可用,但是我一直不生效,我觉得的必须要用管理员权限安装导致的。后来我直接忽略了,用管理员权限运行。
1.1.2 运行服务端
用管理员 power shell 运行 具体命令可以参看文档
.\mongod.exe --dbpath D:\mySoft\mongoDB\data\db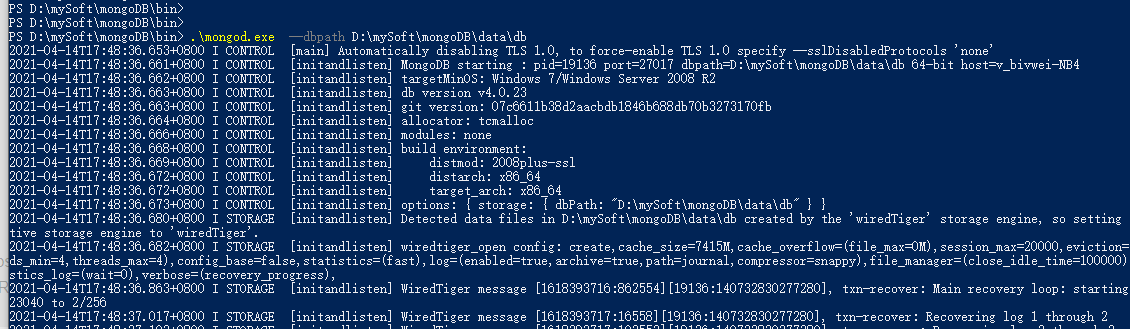
1.1.3 运行客户端
.\mongo.exe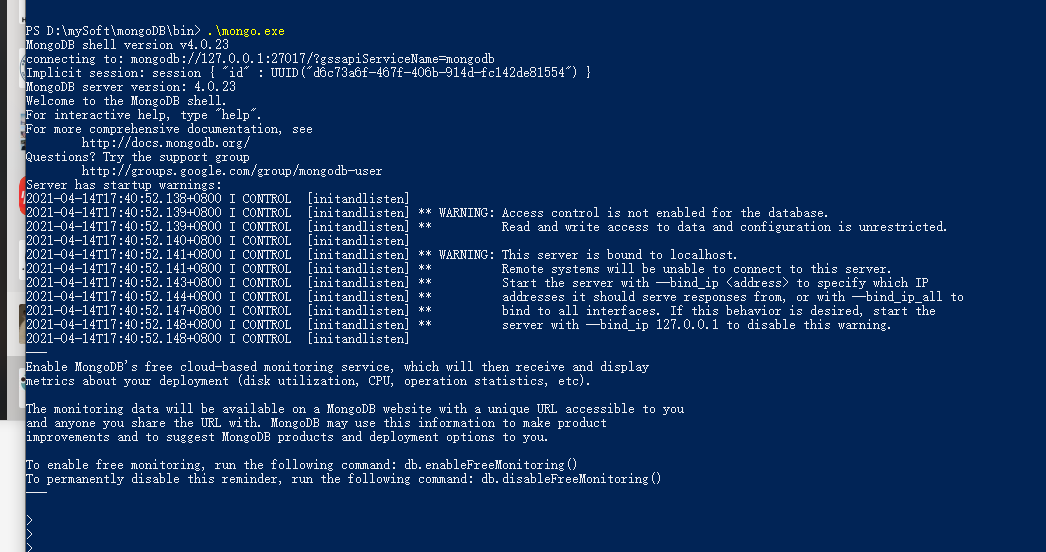
1.2 docker 安装
可以参考 Docker 安装 MongoDB。
arm 架构可以用镜像 arm64v8/mongo。
2 可视化工具
2.1 Navicat Premium
navicat premium 是一个数据库管理工具,可以支持 mysql,mongodb,oracle 等几乎所有的数据库。
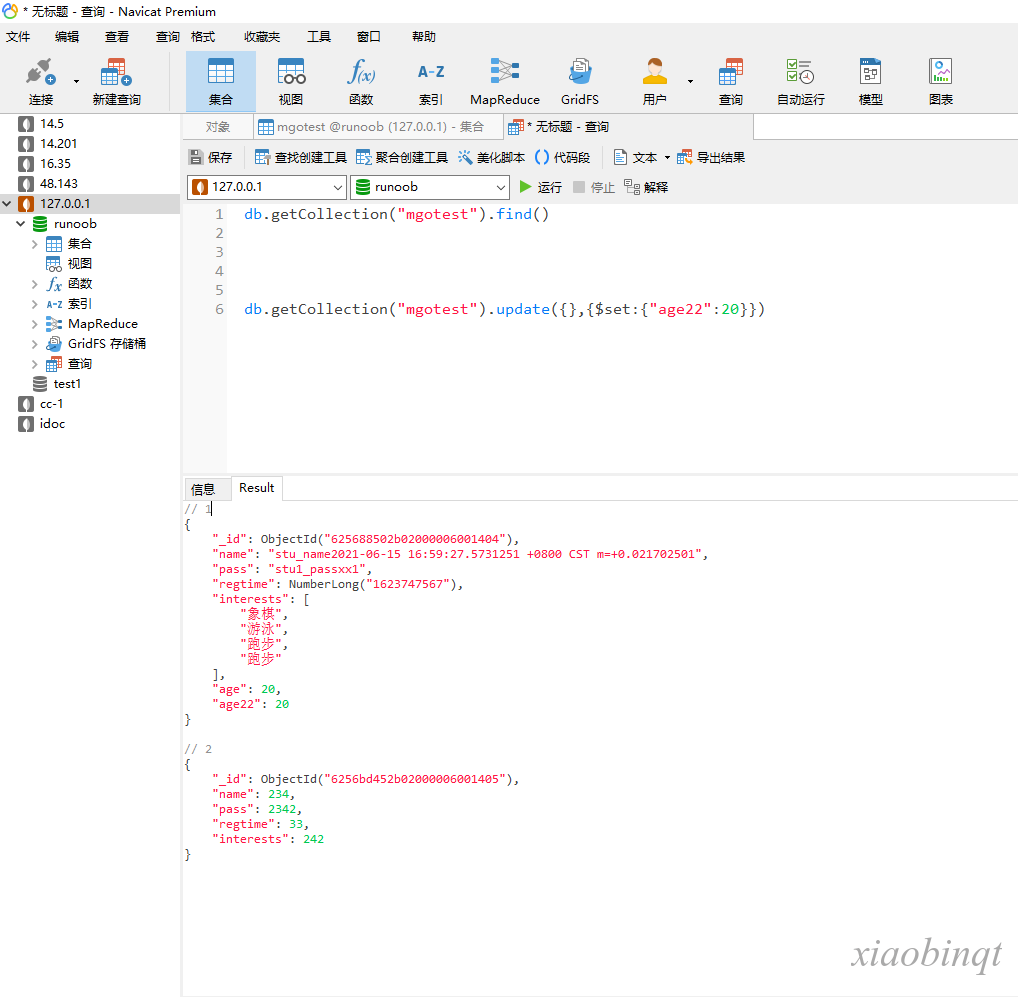
windows 安转教程可以参考navicat premium15破解教程
2.2 mongodb compass
3 概念解析
| SQL术语/概念 | MongoDB术语/概念 | 说明 |
|---|---|---|
| database | database | 数据库 |
| table | collection | 数据库表/集合 |
| row | document | 数据记录行/文档 |
| column | field | 数据字段/域 |
| index | index | 索引 |
| table joins | - | 表连接,MongoDB 不支持 |
| primary key | primary key | 主键,MongoDB 自动将 _id 字段设置为主键 |
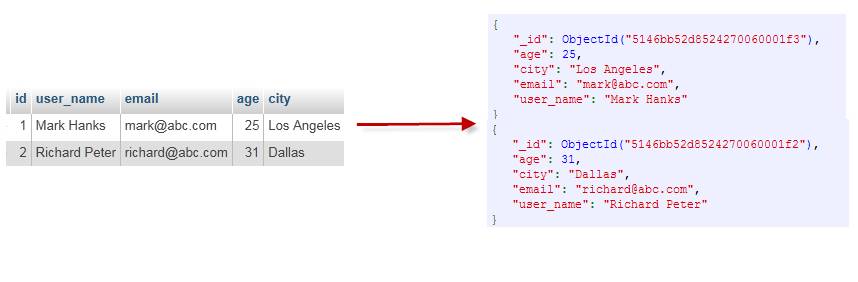
| RDBMS(关系型数据库) | MongoDB |
|---|---|
| 数据库 | 数据库 |
| 表格 | 集合 |
| 行 | 文档 |
| 列 | 字段 |
| 表联合 | 嵌入文档 |
| 主键 | 主键 (MongoDB 提供了 key 为 _id ) |
4 常用命令
| CMD | 说明 |
|---|---|
db.help() |
查看命令帮助 |
show dbs |
查看所有数据库 |
use db_name |
如果数据库不存在,则创建数据库,否则切换到指定数据库 |
show tables |
查看该库下的所有表 |
db.getName() |
查看当前所在的库 |
db |
命令可以显示当前数据库对象或集合 |
db.version() |
当前db版本 |
db.stats() |
当前db状态 |
db.getMongo() |
查看当前db的链接机器地址 |
db.dropDatabase() |
删除当前使用的数据库 |
db.copyDatabase("mydb", "temp", "127.0.0.1") |
从指定的机器上复制指定数据库数据到某个数据库,本示例为:将本机的 mydb 的数据复制到 temp 数据库中 |
db.cloneDatabase("127.0.0.1") |
将指定机器上的数据库的数据克隆到当前数据库 |
db.repairDatabase() |
修复当前数据库 |
show collections/show tables |
查看已有集合 |
db.yourColl.help() |
查看帮助 |
db.yourColl.count() |
查询当前集合的数据条数 |
db.yourColl.dataSize() |
查看数据空间大小 |
db.yourColl.getDB() |
得到当前聚集集合所在的 db |
db.yourColl.stats() |
得到当前集合的状态 |
db.yourColl.totalSize() |
得到集合总大小 |
db.yourColl.storageSize() |
聚集集合储存空间大小 |
db.yourColl.getShardVersion() |
Shard版本信息 |
db.userInfo.renameCollection("users") |
集合重命名。示例为:将 userInfo 重命名为 users |
db.yourColl.drop() |
删除当前集合 |
yourColl表示集合名
5 集合查询
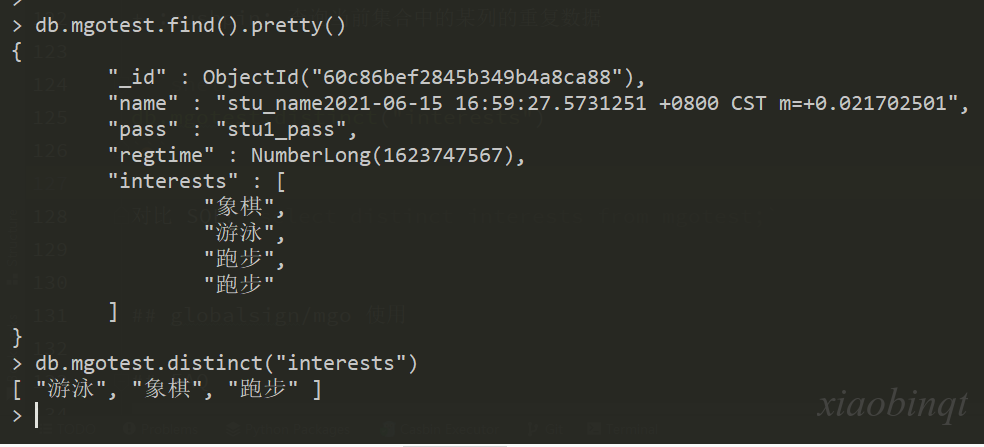
- 📌 查询所有记录
db.mgotest.find()
# 格式化输出
db.mgotest.find().pretty()对比 SQL:select * from mgotest;
- 📌 查询去掉后的当前集合中的某列的重复数据
db.mgotest.distinct("interests")对比 SQL:select distinct interests from mgotest;
- 📌 查询 age = 22 的记录
db.userInfo.find({"age": 22});对比 SQL:select * from userInfo where age = 22;
- 📌 查询 age > 22 的记录
db.userInfo.find({age: {$gt: 22}})对比 SQL:select * from userInfo where age >22;
- 📌 查询 age < 22 的记录
db.userInfo.find({age: {$lt: 22}});对比 SQL:select * from userInfo where age < 22;
- 📌 查询 age >= 25 的记录
db.userInfo.find({age: {$gte: 25}});对比 SQL:select * from userInfo where age >= 25;
- 📌 查询 age <= 25 的记录
db.userInfo.find({age: {$lte: 25}});- 📌 查询 age >= 23 并且 age <= 26
db.userInfo.find({age: {$gte: 23, $lte: 26}});- 📌 查询 name 中包含 mongo 的数据
db.userInfo.find({name: /mongo/});对比 SQL:select * from userInfo where name like ‘%mongo%';
- 📌 查询 name 中以 mongo 开头的
db.userInfo.find({name: /^mongo/});对比 SQL:select * from userInfo where name like ‘mongo%';
- 📌 查询指定列 name、age 数据
db.userInfo.find({}, {name: 1, age: 1});对比 SQL:select name, age from userInfo;
- 📌 查询指定列 name、age 数据, age > 25
db.userInfo.find({age: {$gt: 25}}, {name: 1, age: 1});对比 SQL:select name, age from userInfo where age >25;
- 📌 按照年龄排序
# 升序
db.userInfo.find().sort({age: 1});
# 降序
db.userInfo.find().sort({age: -1});- 📌 查询 name = zhangsan, age = 22 的数据
db.userInfo.find({name: 'zhangsan', age: 22});对比 SQL:select * from userInfo where name = 'zhangsan' and age = '22';
- 📌 查询前 5 条数据
db.userInfo.find().limit(5);对比 SQL:select * from userInfo limit 5;
- 📌 查询 10 条以后的数据
db.userInfo.find().skip(10);对比 SQL:
select *
from userInfo
where id not in (select id
from userInfo limit 10
);- 📌 查询在 5-10 之间的数据
db.userInfo.find().limit(10).skip(5);可用于分页,limit 是 pageSize,skip 是 (第几页 * pageSize)
- 📌 or 查询
db.userInfo.find({$or: [{age: 22}, {age: 25}]});对比 SQL:select * from userInfo where age = 22 or age = 25;
- 📌 查询某个结果集的记录条数
db.userInfo.find({age: {$gte: 25}}).count();对比 SQL:select count(*) from userInfo where age >= 20;
- 📌 按照某列进行排序
db.userInfo.find({sex: {$exists: true}}).count();对比 SQL:select count(sex) from userInfo;
6 更新文档
db.collection.update(
<query>,
<update>,
{
upsert: <boolean>,
multi: <boolean>,
writeConcern: <document>
}
)
# 示例
db.col.update({'title':'MongoDB 教程'},{$set:{'title':'MongoDB'}})参数说明:
- query : update 的查询条件,类似 sql update 查询内 where 后面的。
- update : update 的对象和一些更新的操作符(如$,$inc…)等,也可以理解为 sql update 查询内 set 后面的
- upsert : 可选,这个参数的意思是,如果不存在 update 的记录,是否插入 objNew, true 为插入,默认是 false ,不插入。
- multi : 可选,mongodb 默认是 false,只更新找到的第一条记录,如果这个参数为 true, 就把按条件查出来多条记录全部更新。
- writeConcern :可选,抛出异常的级别。
6.1 $push
$push 操作符添加指定的值到数组中,不去重。
6.2 $addToSet
$addToSet 这个方法向数组中增加值,自动去重。
7 globalsign/mgo 使用
globalsign/mgo 是 Go 的 MongoDB 驱动,我现在维护的项目也在使用这个,在这里简单介绍一下。
package main
import (
"fmt"
"time"
"github.com/globalsign/mgo"
"github.com/globalsign/mgo/bson"
)
type User struct {
Id bson.ObjectId `bson:"_id" json:"id"`
Username string `bson:"name" json:"username"`
Pass string `bson:"pass" json:"pass"`
Regtime int64 `bson:"regtime" json:"regtime"`
Interests []string `bson:"interests" json:"interests"`
}
const URL string = "127.0.0.1:27017"
var (
c *mgo.Collection
session *mgo.Session
)
func (user User) ToString() string {
return fmt.Sprintf("%#v", user)
}
func init() {
session, _ = mgo.Dial(URL)
// 切换到数据库
db := session.DB("blog")
// 切换到collection
c = db.C("mgotest")
}
// 新增数据
func add() {
// defer session.Close()
stu1 := new(User)
stu1.Id = bson.NewObjectId()
stu1.Username = "stu_name" + time.Now().String()
stu1.Pass = "stu1_pass"
stu1.Regtime = time.Now().Unix()
stu1.Interests = []string{"象棋", "游泳", "跑步"}
err := c.Insert(stu1)
if err == nil {
fmt.Println("insert success")
} else {
fmt.Printf("insert error:%s \n", err.Error())
}
}
// 查询
func find() {
// defer session.Close()
var (
users []User
err error
)
// c.Find(nil).All(&users)
err = c.Find(bson.M{"name": "stu_name"}).All(&users)
if err != nil {
fmt.Printf("find err:%s \n", err.Error())
return
}
for index, value := range users {
fmt.Printf("index:%d,val:%s \n", index, value.ToString())
}
// 根据ObjectId进行查询
// idStr := "577fb2d1cde67307e819133d"
// objectId := bson.ObjectIdHex(idStr)
// user := new(User)
// err = c.Find(bson.M{"_id": objectId}).One(user)
// if err != nil {
// fmt.Printf("db find err:%s \n", err.Error())
// return
// }
// fmt.Println("查找成功..", user)
}
// 根据id进行修改
func update() {
interests := []string{"象棋", "游泳", "跑步"}
err := c.Update(bson.M{"_id": bson.ObjectIdHex("6076c3954e947b3944d4a38b")}, bson.M{"$set": bson.M{
"name": "修改后的name",
"pass": "修改后的pass",
"regtime": time.Now().Unix(),
"interests": interests,
}})
if err != nil {
fmt.Println("修改失败")
} else {
fmt.Println("修改成功")
}
}
// 删除
func del() {
err := c.Remove(bson.M{"_id": bson.ObjectIdHex("6076c3954e947b3944d4a38b")})
if err != nil {
fmt.Println("删除失败" + err.Error())
} else {
fmt.Println("删除成功")
}
}
func main() {
add()
find()
update()
del()
}8 角色
对于非 admin 库,不能拥有clusterAdmin、readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase这些角色。
MongoDB 目前内置了 7 个角色。
- 数据库用户角色:
read、readWrite; - 数据库管理角色:
dbAdmin、dbOwner、userAdmin; - 集群管理角色:
clusterAdmin、clusterManager、clusterMonitor、hostManager; - 备份恢复角色:
backup、restore; - 所有数据库角色:
readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase - 超级用户角色 root;这里还有几个角色间接或直接提供了系统超级用户的访问(
dbOwner、userAdmin、userAdminAnyDatabase) - 内部角色:
__system
这些角色对应的作用如下:
Read:允许用户读取指定数据库readWrite:允许用户读写指定数据库dbAdmin:允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profileuserAdmin:允许用户向system.users集合写入,可以找指定数据库里创建、删除和管理用户clusterAdmin:只在 admin 数据库中可用,赋予用户所有分片和复制集相关函数的管理权限。readAnyDatabase:只在 admin 数据库中可用,赋予用户所有数据库的读权限readWriteAnyDatabase:只在 admin 数据库中可用,赋予用户所有数据库的读写权限userAdminAnyDatabase:只在 admin 数据库中可用,赋予用户所有数据库的 userAdmin 权限dbAdminAnyDatabase:只在 admin 数据库中可用,赋予用户所有数据库的 dbAdmin 权限。root:只在 admin 数据库中可用。超级账号,超级权限
一般在新建用户时常见的错误有👇
uncaught exception: Error: couldn’t add user: No role named userAdminAnyDatabase@xxxxxx
9 FAQ
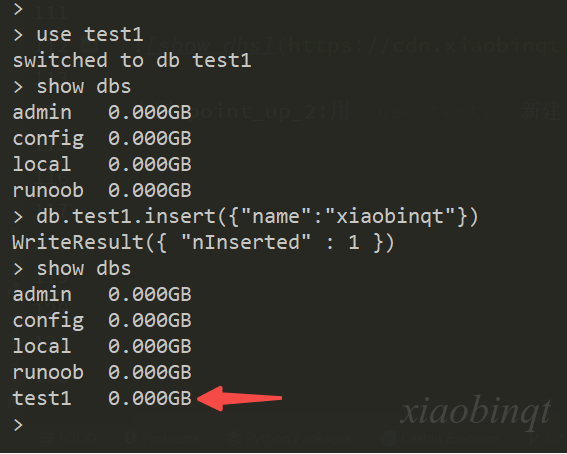
9.1 空库不显示
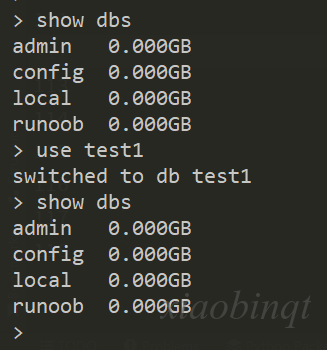
上图👆用 use test1 新建了一个数据库 test1,但是用 show dbs 却没有显示 test1,这是因为 test1 是空的,插入一条数据就可以显示。
9.2 定长表
最近有个需求是,需要某个集合实现只保留固定数量的记录,自动淘汰老旧数据。
通过创建集合的命令 db.createCollection(name, options) 可知,有个可选的 options 参数:
参数说明:
- name: 要创建的集合名称
- options: 可选参数, 指定有关内存大小及索引的选项
options 可以是如下参数:
| 字段 | 类型 | 描述 |
|---|---|---|
| capped | 布尔 | (可选)如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。当该值为 true 时,必须指定 size 参数。 |
| autoIndexId | 布尔 | 3.2 之后不再支持该参数。(可选)如为 true,自动在 _id 字段创建索引。默认为 false。 |
| size | 数值 | (可选)为固定集合指定一个最大值,即字节数 。如果 capped 为 true,也需要指定该字段。 |
| max | 数值 | (可选)指定固定集合中包含文档的最大数量。 |
如果是新建一个集合,这种方式肯定是可以的,但是如果要同步老数据呢?
比如我有一个集合 daily_report 集合,里面有一些老数据:
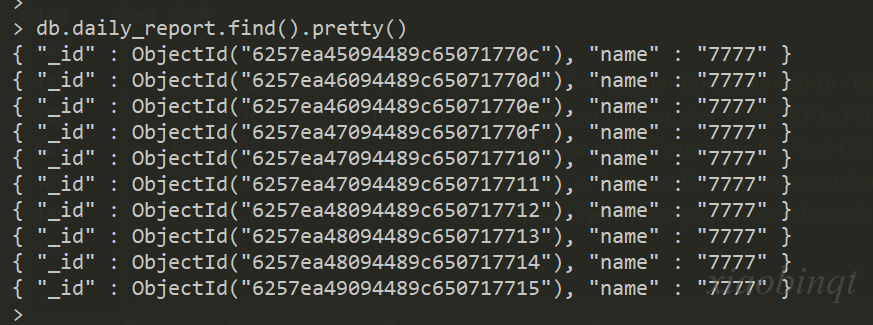
我的想法是,将 daily_report 重命名为 daily_report_bak,新建集合 daily_report,就 daily_report_bak 数据同步到 daily_report。
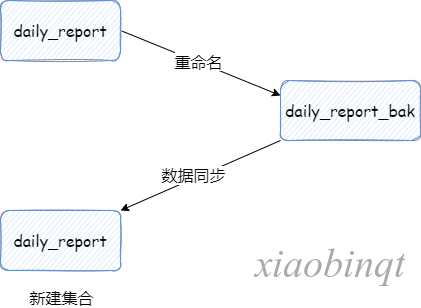
重命名集合:
db.daily_report.renameCollection("daily_report_bak")新建集合:
db.createCollection("daily_report", {capped:true,size:6142800,max:4})该集合最大值字节数为:6142800字节 = 6142800B ≈ 6000KB ≈ 5M 。
该集合中包含文档的最大数量为 4 条。
同步旧数据
db.daily_report_bak.find().forEach(function(doc){db.daily_report.insert(doc)})