2.20 网络通信 #
2.20.1 网络模型 #
Docker 有三种常见的网络模式: null、host 和 bridge。下图,描述了 Docker 里最常用的 bridge 网络模式:
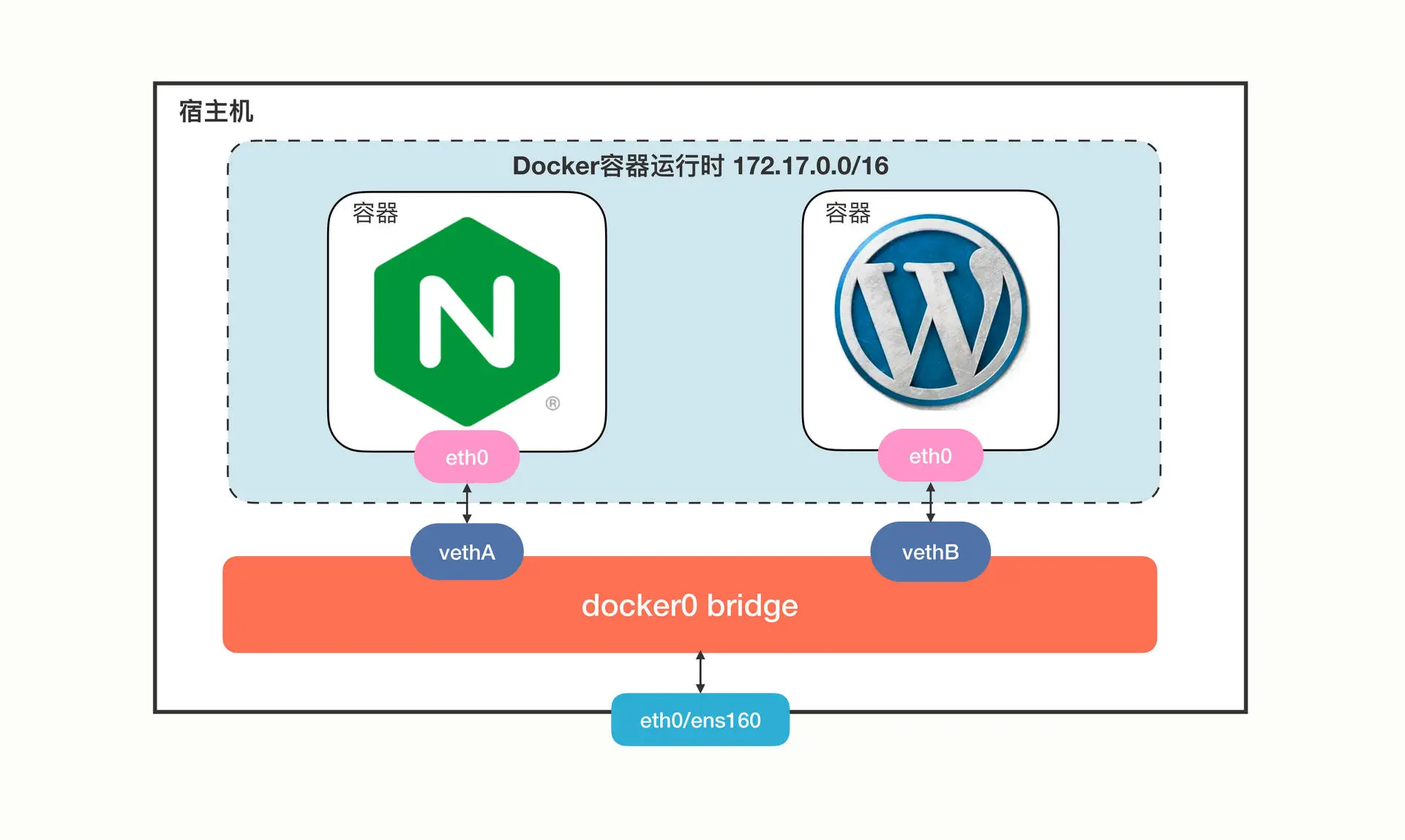
Docker 会创建一个名字叫 “docker0” 的网桥,默认是私有网段 “172.17.0.0/16”。每个容器都会创建一个虚拟网卡对(veth pair),两个虚拟网卡分别 “插” 在容器和网桥上,这样容器之间就可以互联互通了。Docker 的网络方案简单有效,但只局限在单机环境里工作,跨主机通信非常困难(需要做端口映射和网络地址转换)。
Kubernetes 的网络模型 “IP-per-pod”,能够很好地适应集群系统的网络需求,它有下面的这 4 点基本假设:
-
集群里的每个 Pod 都会有唯一的一个 IP 地址。
-
Pod 里的所有容器共享这个 IP 地址。
-
集群里的所有 Pod 都属于同一个网段。
-
Pod 直接可以基于 IP 地址直接访问另一个 Pod,不需要做麻烦的网络地址转换(NAT)。
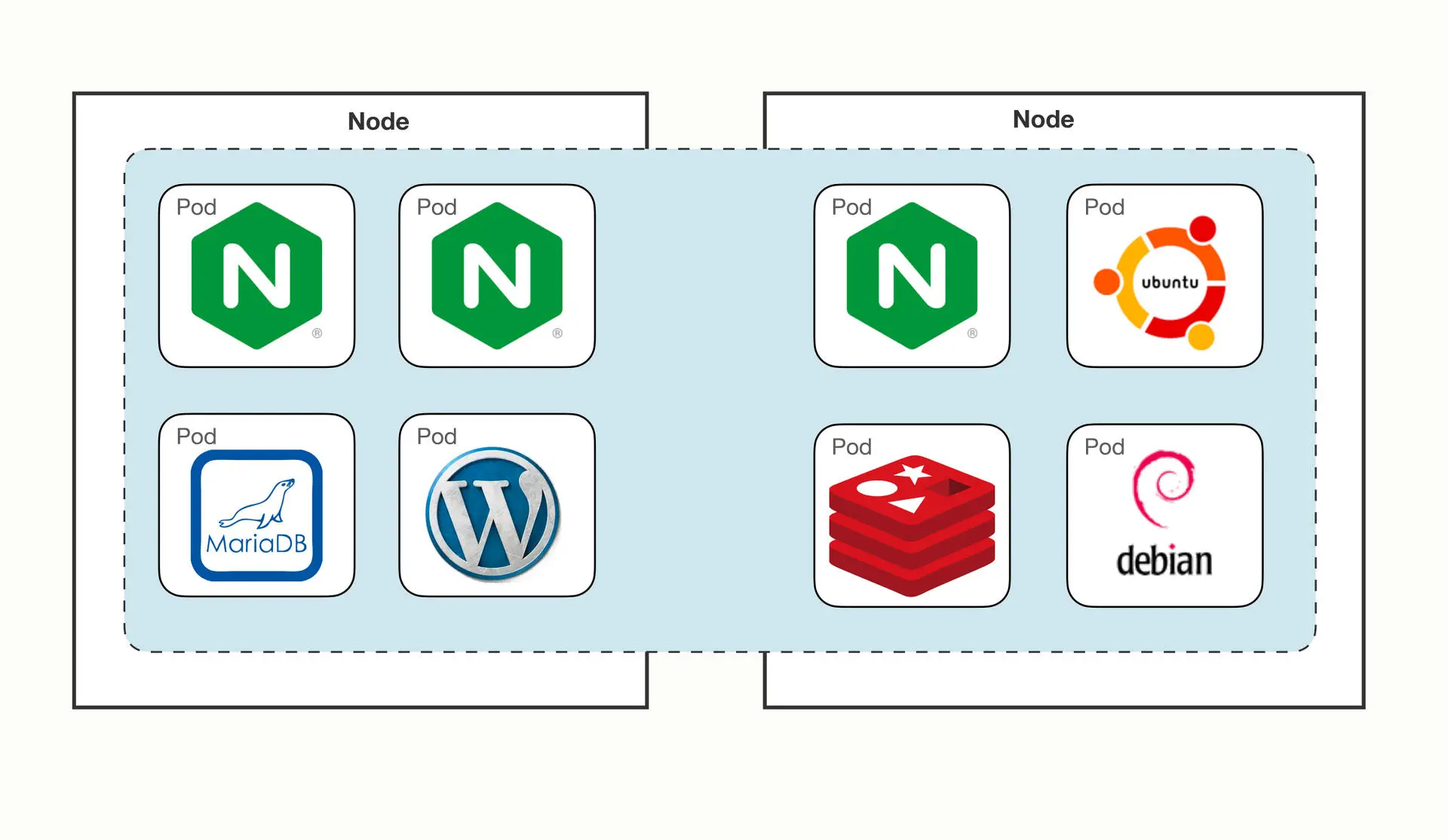
这种网络让 Pod 摆脱了主机的硬限制,是一个 “平坦” 的网络模型,通信也非常简单。因为 Pod 都具有独立的 IP 地址,相当于一台虚拟机,而且直连互通,也就可以很容易地实施域名解析、负载均衡、服务发现等工作,对应用的管理和迁移都非常友好。
2.20.2 什么是 CNI #
CNI(Container Networking Interface)为网络插件定义了一系列通用接口,开发者只要遵循这个规范就可以接入 Kubernetes,为 Pod 创建虚拟网卡、分配 IP 地址、设置路由规则,最后就能够实现 “IP-per-pod” 网络模型。依据实现技术的不同,CNI 插件可以大致上分成 “Overlay” “Route” 和 “Underlay” 三种。
Overlay 是指它构建了一个工作在真实底层网络之上的 “逻辑网络”,把原始的 Pod 网络数据封包,再通过下层网络发送出去,到了目的地再拆包。因为这个特点,它对底层网络的要求低,适应性强,缺点就是有额外的传输成本,性能较低。
Route 也是在底层网络之上工作,但它没有封包和拆包,而是使用系统内置的路由功能来实现 Pod 跨主机通信。它的好处是性能高,不过对底层网络的依赖性比较强,如果底层不支持就没办法工作了。
Underlay 就是直接用底层网络来实现 CNI,也就是说 Pod 和宿主机都在一个网络里,Pod 和宿主机是平等的。它对底层的硬件和网络的依赖性是最强的,因而不够灵活,但性能最高。
常见插件 #
Flannel https://github.com/flannel-io/flannel/ 最早是一种 Overlay 模式的网络插件,使用 UDP 和 VXLAN 技术,后来又用 Host-Gateway 技术支持了 Route 模式。Flannel 简单易用,是 Kubernetes 里最流行的 CNI 插件,但它在性能方面表现不太好,一般不建议在生产环境中使用。
Calico https://github.com/projectcalico/calico 是一种 Route 模式的网络插件,使用 BGP 协议(Border Gateway Protocol)来维护路由信息,性能比 Flannel 好,而且支持多种网络策略,具备数据加密、安全隔离、流量整形等功能。
Cilium https://github.com/cilium/cilium 同时支持 Overlay 模式和 Route 模式,特点是深度使用了 Linux eBPF 技术,在内核层次操作网络数据,性能很高,可以灵活实现各种功能,是非常有前途的 CNI 插件。
2.20.3 CNI 插件工作方式 #
以 Flannel 为例,看看 CNI 在 Kubernetes 里的工作方式。
先用 Deployment 创建 3 个 Nginx Pod,作为研究对象:
kubectl create deploy ngx-dep --image=nginx:alpine --replicas=3

使用命令 kubectl get pod 可以看到,有两个 Pod 运行在 master 节点上,另一个 Pod 运行在 worker 节点上。
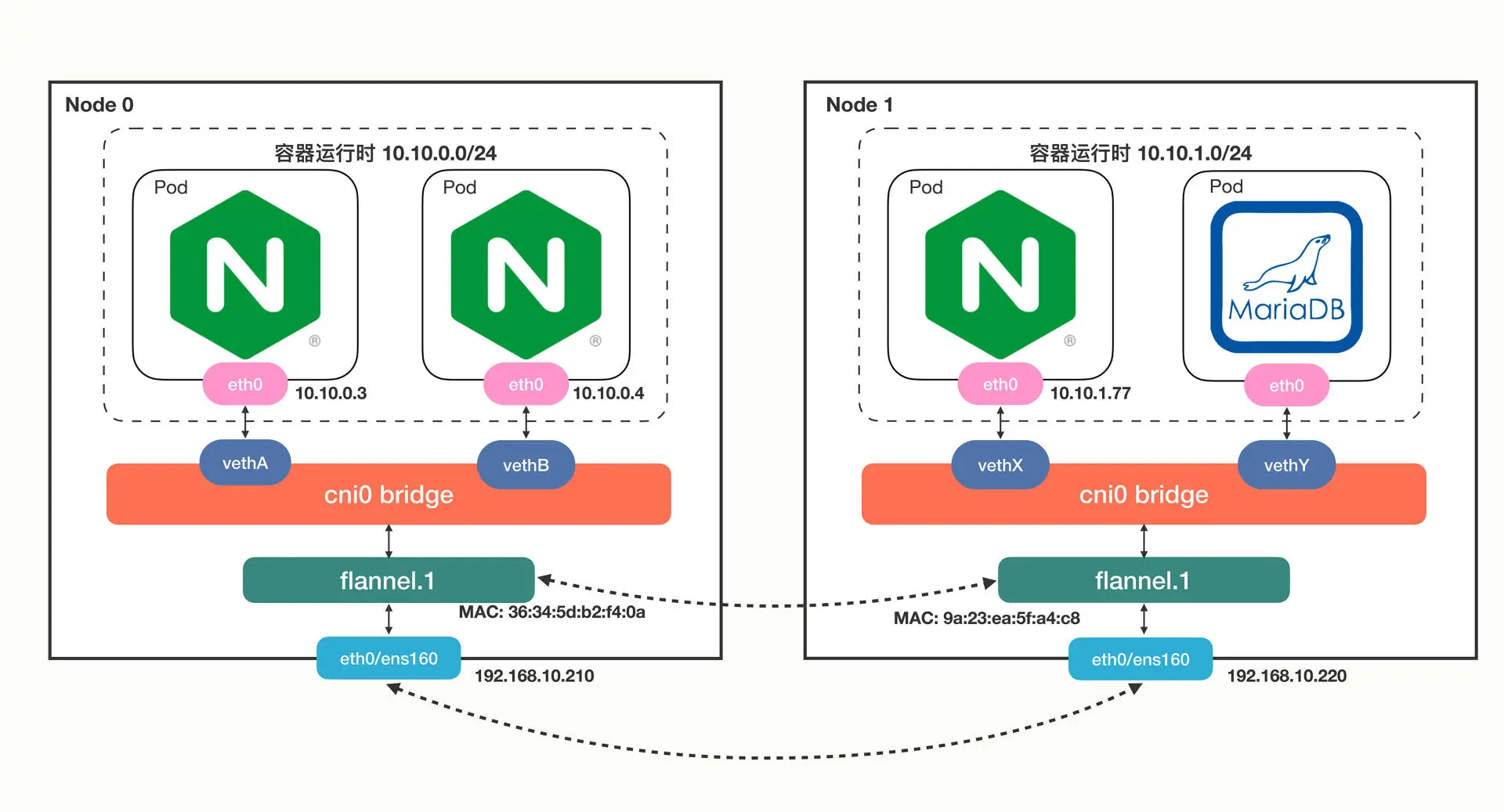
Flannel 默认使用的是基于 VXLAN 的 Overlay 模式,整个集群的网络结构如下:
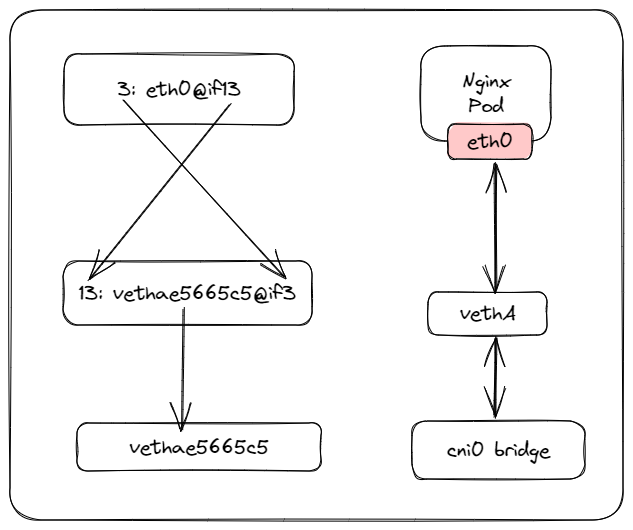
在 Pod 里执行命令 ip addr 就可以看到它里面的虚拟网卡 “eth0”:
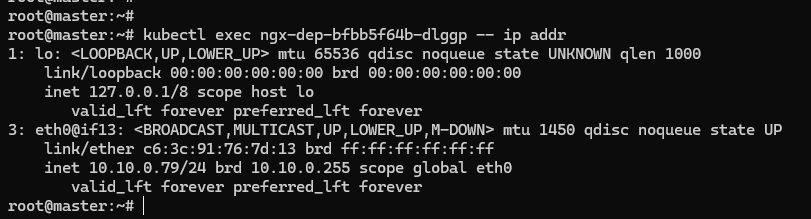
第一个数字 “3” 是序号,意思是第 3 号设备,“@if13” 就是它另一端连接的虚拟网卡,序号是 13。
这个 Pod 的宿主机是 master,可以登录到 master 节点,看看这个节点上的网络情况,同样还是用命令 ip addr:
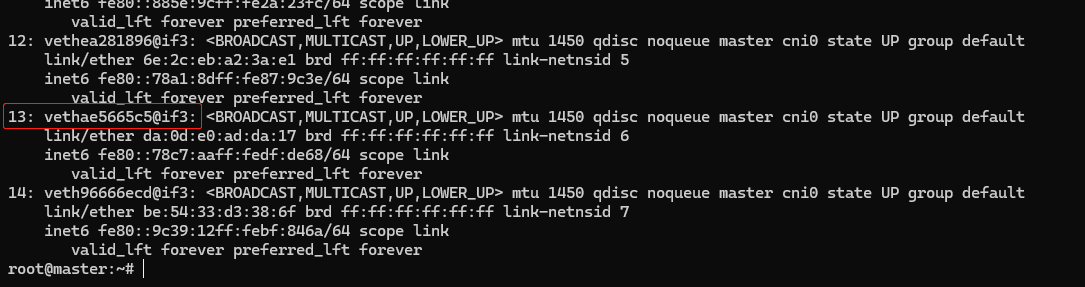
这里就可以看到 master 节点上的第 13 号设备了,它的名字是 vethae5665c5@if3,“veth” 表示它是一个虚拟网卡,而后面的 “@if3” 就是 Pod 里对应的 3 号设备,也就是 “eth0” 网卡了。
“cni0” 网桥的信息可以在 master 节点上使用命令 brctl show:
如果没有 brctl 命令可以通过 apt install bridge-utils 安装
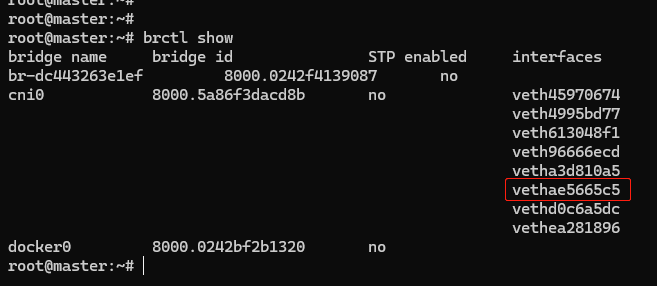
可以看到 “cni0” 网桥上有一个 “vethae5665c5” 网卡,所以这个网卡就被 “插” 在了 “cni0” 网桥上,因为虚拟网卡的 “结对” 特性,Pod 也就连上了 “cni0” 网桥。
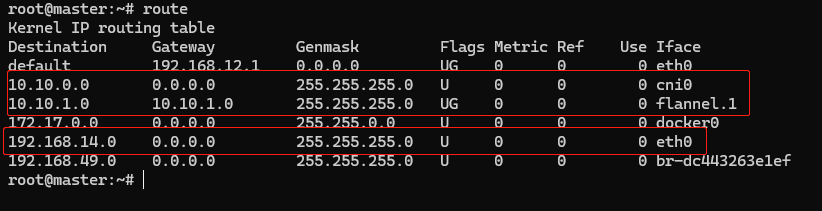
关于跨主机网络,关键是节点的路由表,可以用命令 route 查看:
-
10.10.0.0/24 网段的数据,都要走 cni0 设备,也就是 “cni0” 网桥。
-
10.10.1.0/24 网段的数据,都要走 flannel.1 设备,也就是 Flannel。
-
192.168.14.0/24 网段的数据,都要走 eth0 设备,也就是宿主机的网卡。
假设要从 master 节点的 10.10.0.3 访问 worker 节点的 10.10.1.77,因为 master 节点的 “cni0” 网桥管理的只是 10.10.0.0/24 这个网段,所以按照路由表,凡是 10.10.1.0/24 都要让 flannel.1 来处理,这样就进入了 Flannel 插件的工作流程。
Flannel 将要决定如何把数据发到另一个节点,在各种表里去查询。如下图,用到的命令有 ip neighbor、bridge fdb 等:
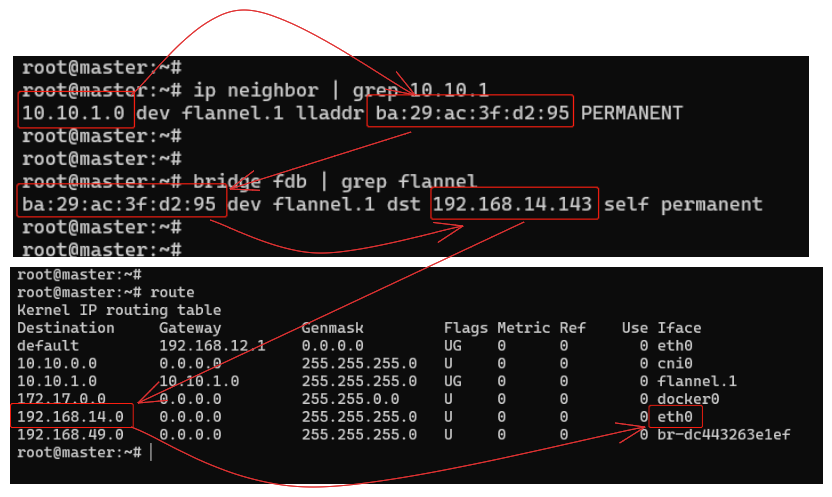
Flannel 得到的结果就是要把数据发到 192.168.14.143 worker 节点,它会在原始网络包前面加上这些额外的信息,封装成 VXLAN 报文,用 eth0 网卡发出去,worker 节点收到后再拆包,执行类似的反向处理,就可以把数据交给真正的目标 Pod 了。
2.20.4 Calico 网络插件 #
可以在 Calico 的网站 https://www.tigera.io/project-calico/ 上找到它的安装方式,这里选择 “本地自助安装(Self-managed on-premises)”,直接下载 YAML 文件:
wget https://projectcalico.docs.tigera.io/archive/v3.23/manifests/calico.yaml
由于 Calico 使用的镜像比较大,为了加快安装速度,可以考虑在每个节点上预先使用 docker pull 拉取镜像:
docker pull calico/cni:v3.23.5
docker pull calico/node:v3.23.5
docker pull calico/kube-controllers:v3.23.5
Calico 的安装只需要用 kubectl apply calico.yaml 就可以。如果有安装 Flannel 插件,最好先把 Flannel 删除:
kubectl apply -f calico.yaml
查看一下 Calico 的运行状态,它也是在 “kube-system” 名字空间: