2.19 系统监控 #
2.19.1 Metrics Server #
Linux top 命令能够实时显示当前系统的 CPU 和内存利用率,是性能分析和调优的工具。Kubernetes 也提供了类似的命令,就是 kubectl top,不过默认情况下这个命令不会生效,必须要安装插件 Metrics Server 才可以。
Metrics Server 是一个专门用来收集 Kubernetes 核心资源指标(metrics)的工具,它定时从所有节点的 kubelet 里采集信息,但是对集群的整体性能影响极小,每个节点只大约会占用 1m 的 CPU 和 2MB 的内存,性价比非常高。项目网址在 https://github.com/kubernetes-sigs/metrics-server。
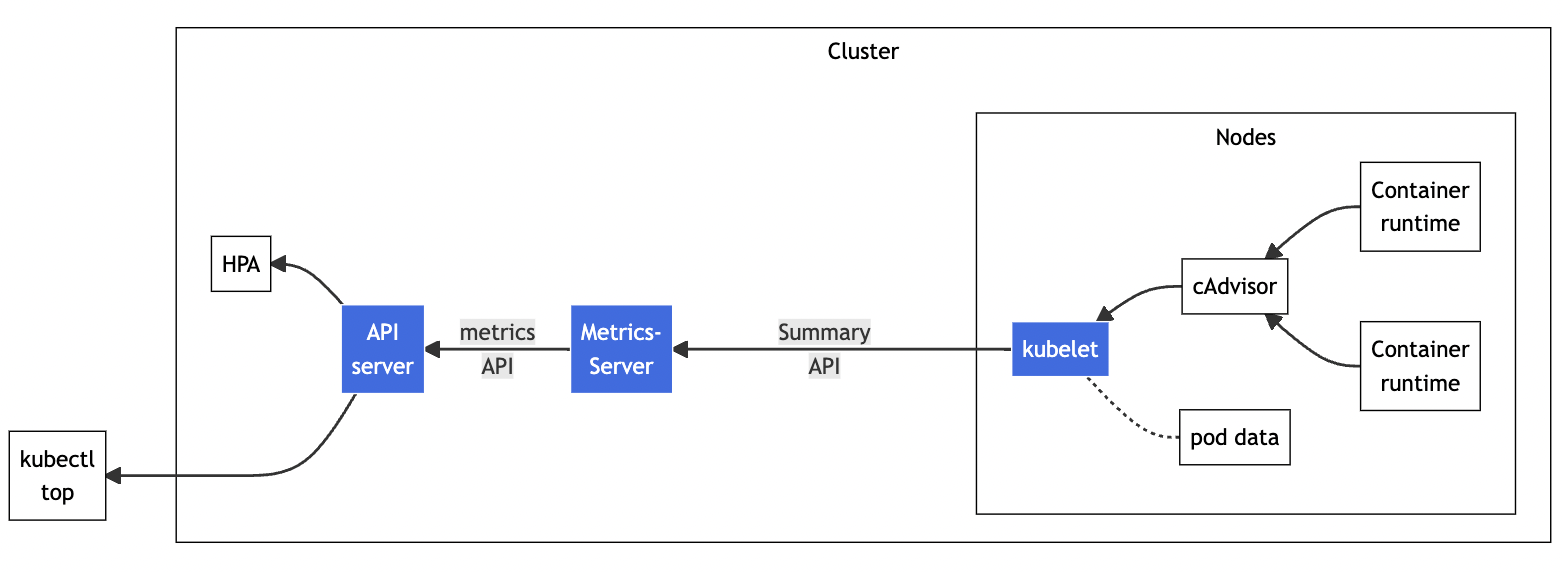
Metrics Server 调用 kubelet 的 API 拿到节点和 Pod 的指标,再把这些信息交给 apiserver,这样 kubectl、HPA 就可以利用 apiserver 来读取指标了。
Metrics Server 的所有依赖都放在了一个 YAML 描述文件里,你可以使用 wget 或者 curl 下载:
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
下载下来的 YAML 描述文件不能直接使用,需要修改下。
- 需要在 Metrics Server 的 Deployment 对象里,加上一个额外的运行参数
--kubelet-insecure-tls,也就是这样:
apiVersion: apps/v1
kind: Deployment
metadata:
name: metrics-server
namespace: kube-system
spec:
... ...
template:
spec:
containers:
- args:
- --kubelet-insecure-tls
... ...
Metrics Server 默认使用 TLS 协议,要验证证书才能与 kubelet 实现安全通信,加上这个参数可以让部署工作简单很多(生产环境里就要慎用)。
- Metrics Server 的镜像仓库用的是 gcr.io,在国内下载很困难。可以通过科学上网的方式,下载后把镜像加载到集群里的节点上。如果已经可以科学上网可以忽略这项。
完整的 components.yaml 如下:
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
rbac.authorization.k8s.io/aggregate-to-admin: "true"
rbac.authorization.k8s.io/aggregate-to-edit: "true"
rbac.authorization.k8s.io/aggregate-to-view: "true"
name: system:aggregated-metrics-reader
rules:
- apiGroups:
- metrics.k8s.io
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
rules:
- apiGroups:
- ""
resources:
- nodes/metrics
verbs:
- get
- apiGroups:
- ""
resources:
- pods
- nodes
verbs:
- get
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server-auth-reader
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: extension-apiserver-authentication-reader
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: metrics-server:system:auth-delegator
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:auth-delegator
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
k8s-app: metrics-server
name: system:metrics-server
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:metrics-server
subjects:
- kind: ServiceAccount
name: metrics-server
namespace: kube-system
---
apiVersion: v1
kind: Service
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
ports:
- name: https
port: 443
protocol: TCP
targetPort: https
selector:
k8s-app: metrics-server
---
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
k8s-app: metrics-server
name: metrics-server
namespace: kube-system
spec:
selector:
matchLabels:
k8s-app: metrics-server
strategy:
rollingUpdate:
maxUnavailable: 0
template:
metadata:
labels:
k8s-app: metrics-server
spec:
containers:
- args:
- --kubelet-insecure-tls
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
image: registry.k8s.io/metrics-server/metrics-server:v0.6.3
imagePullPolicy: IfNotPresent
livenessProbe:
failureThreshold: 3
httpGet:
path: /livez
port: https
scheme: HTTPS
periodSeconds: 10
name: metrics-server
ports:
- containerPort: 4443
name: https
protocol: TCP
readinessProbe:
failureThreshold: 3
httpGet:
path: /readyz
port: https
scheme: HTTPS
initialDelaySeconds: 20
periodSeconds: 10
resources:
requests:
cpu: 100m
memory: 200Mi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
runAsNonRoot: true
runAsUser: 1000
volumeMounts:
- mountPath: /tmp
name: tmp-dir
nodeSelector:
kubernetes.io/os: linux
priorityClassName: system-cluster-critical
serviceAccountName: metrics-server
volumes:
- emptyDir: { }
name: tmp-dir
---
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
labels:
k8s-app: metrics-server
name: v1beta1.metrics.k8s.io
spec:
group: metrics.k8s.io
groupPriorityMinimum: 100
insecureSkipTLSVerify: true
service:
name: metrics-server
namespace: kube-system
version: v1beta1
versionPriority: 100
准备工作完成后,就可以使用 YAML 部署 Metrics Server 了:
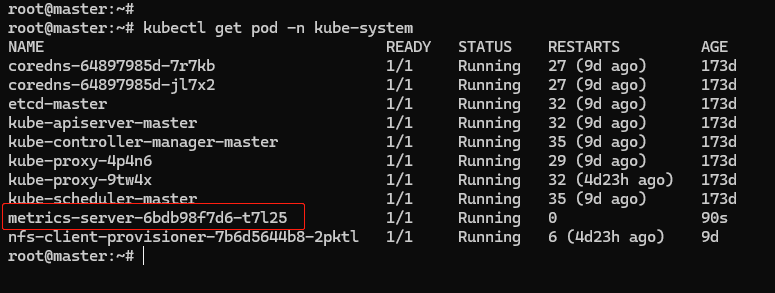
Metrics Server 属于名字空间 “kube-system”,可以用 kubectl get pod 加上 -n 参数查看是否正常运行:
kubectl get pod -n kube-system
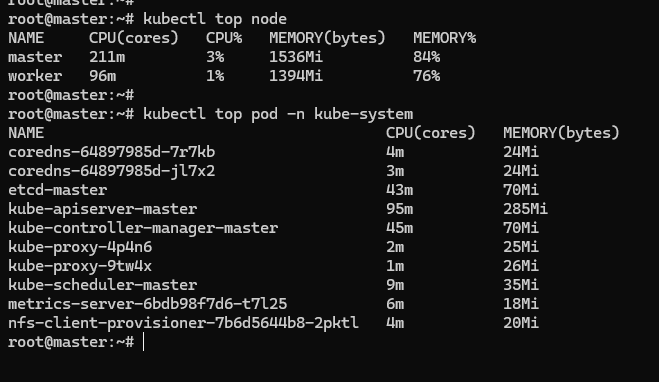
有了 Metrics Server 插件,就可以使用命令 kubectl top 来查看 Kubernetes 集群当前的资源状态了。它有两个子命令,node 查看节点的资源使用率,pod 查看 Pod 的资源使用率。
kubectl top node
kubectl top pod -n kube-system
2.19.2 HorizontalPodAutoscaler #
Metrics Server 可以轻松地查看集群的资源使用状况,但是它另外一个更重要的功能是辅助实现应用的 “水平自动伸缩”。
kubectl scale 命令可以任意增减 Deployment 部署的 Pod 数量,也就是水平方向的 “扩容” 和 “缩容”。但是手动调整应用实例数量比较麻烦,需要人工参与,也很难准确把握时机,难以及时应对生产环境中突发的大流量,最好能把 “扩容” “缩容” 变成自动化的操作,这在 Kubernetes 里就是 API “HorizontalPodAutoscaler” 的能力,简称是 “hpa”。
HorizontalPodAutoscaler 的能力完全基于 Metrics Server,它从 Metrics Server 获取当前应用的运行指标,主要是 CPU 使用率,再依据预定的策略增加或者减少 Pod 的数量。
使用 HorizontalPodAutoscaler,首先要定义 Deployment 和 Service,创建一个 Nginx 应用,作为自动伸缩的目标对象:
apiVersion: apps/v1
kind: Deployment
metadata:
name: ngx-hpa-dep
spec:
replicas: 1
selector:
matchLabels:
app: ngx-hpa-dep
template:
metadata:
labels:
app: ngx-hpa-dep
spec:
containers:
- image: nginx:alpine
name: nginx
ports:
- containerPort: 80
resources:
requests:
cpu: 50m
memory: 10Mi
limits:
cpu: 100m
memory: 20Mi
---
apiVersion: v1
kind: Service
metadata:
name: ngx-hpa-svc
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: ngx-hpa-dep
在这个 YAML 里只部署了一个 Nginx 实例,名字是 ngx-hpa-dep。在它的 spec 里一定要用 resources 字段写清楚资源配额,否则 HorizontalPodAutoscaler 会无法获取 Pod 的指标,就无法实现自动化扩缩容。
可以使用 kubectl autoscale 命令创建一个 HorizontalPodAutoscaler 的样板 YAML 文件,它有三个参数:
-
min,Pod 数量的最小值,也就是缩容的下限。
-
max,Pod 数量的最大值,也就是扩容的上限。
-
cpu-percent,CPU 使用率指标,当大于这个值时扩容,小于这个值时缩容。
为刚才的 Nginx 应用创建 HorizontalPodAutoscaler,指定 Pod 数量最少 2 个,最多 10 个,CPU 使用率指标设置的小一点,5%,方便观察扩容现象:
export out="--dry-run=client -o yaml" # 定义Shell变量
kubectl autoscale deploy ngx-hpa-dep --min=2 --max=10 --cpu-percent=5 $out
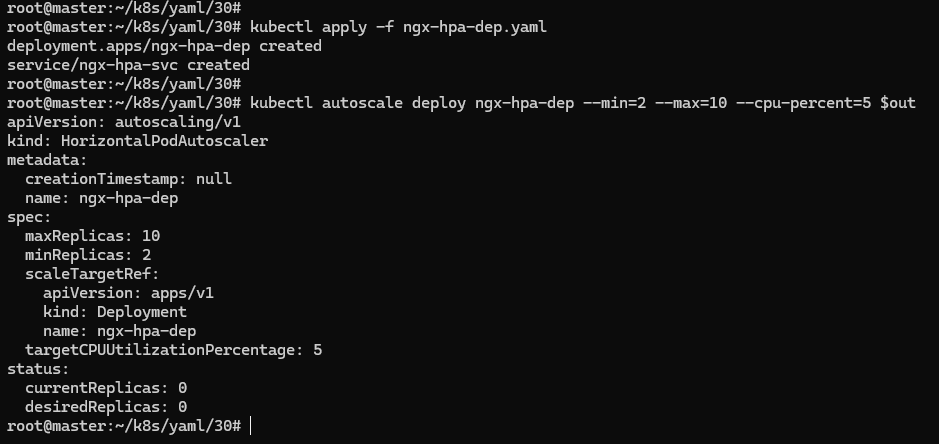
得到的 YAML 描述文件就是如下:
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: ngx-hpa-dep
spec:
maxReplicas: 10
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: ngx-hpa-dep
targetCPUUtilizationPercentage: 5
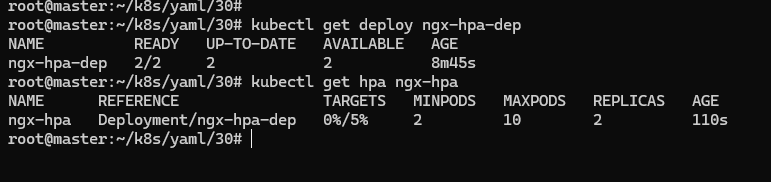
apply 这个 YAML 描述,创建 HorizontalPodAutoscaler 后,它会发现 Deployment 里的实例只有 1 个,不符合 min 定义的下限的要求,就先扩容到 2 个:
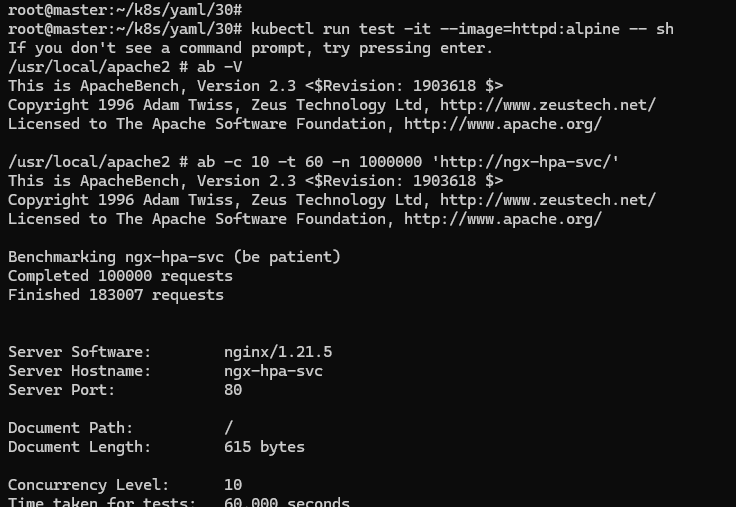
可以给 Nginx 加上压力流量,运行一个测试 Pod,使用的镜像是 “httpd:alpine”,它里面有 HTTP 性能测试工具 ab(Apache Bench):
kubectl run test -it --image=httpd:alpine -- sh
然后向 Nginx 发送一百万个请求,持续 1 分钟,再用 kubectl get hpa 来观察 HorizontalPodAutoscaler 的运行状况:
ab -c 10 -t 60 -n 1000000 'http://ngx-hpa-svc/'
因为 Metrics Server 大约每 15 秒采集一次数据,所以 HorizontalPodAutoscaler 的自动化扩容和缩容也是按照这个时间点来逐步处理的。
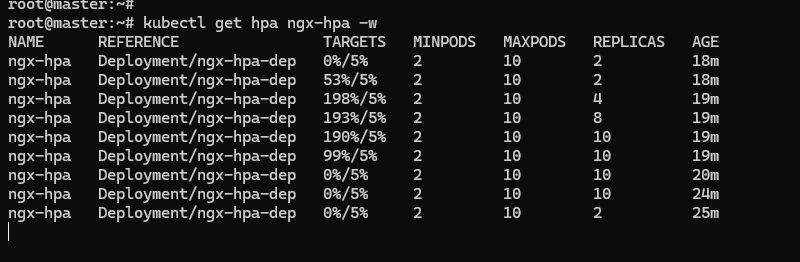
当它发现目标的 CPU 使用率超过了预定的 5% 后,就会以 2 的倍数开始扩容,一直到数量上限,然后持续监控一段时间,如果 CPU 使用率回落,就会再缩容到最小值。
2.19.3 Prometheus #
Metrics Server 能够获取的指标太少,只有 CPU 和内存,而想要监控到更多更全面的应用运行状况,需要用到权威项目 Prometheus,它是云原生监控领域的 “事实标准”。
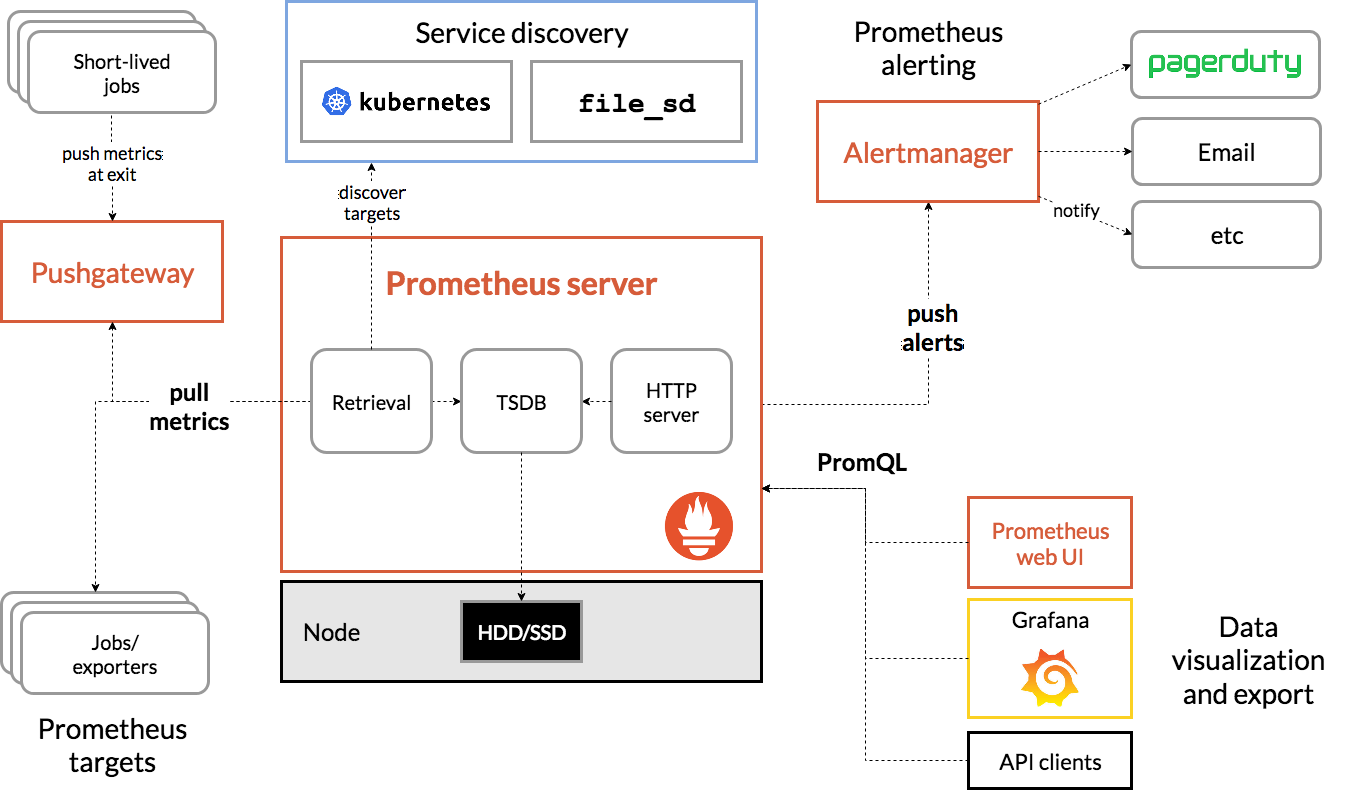
Prometheus 系统的核心是 Server,里面有一个时序数据库 TSDB,用来存储监控数据,另一个组件 Retrieval 使用拉取(Pull)的方式从各个目标收集数据,再通过 HTTP Server 把这些数据交给外界使用。
在 Prometheus Server 之外还有三个重要的组件:
-
Push Gateway,用来适配一些特殊的监控目标,把默认的 Pull 模式转变为 Push 模式。
-
Alert Manager,告警中心,预先设定规则,发现问题时就通过邮件等方式告警。
-
Grafana 是图形化界面,可以定制大量直观的监控仪表盘。
由于 prometheus 包含的组件太多,部署起来麻烦,这里可以使用 “kube-prometheus” 项目 https://github.com/prometheus-operator/kube-prometheus/,操作起来相对容易。
先下载 kube-prometheus 的源码包,这里使用的版本是 0.11:
wget https://github.com/prometheus-operator/kube-prometheus/archive/refs/tags/v0.11.0.tar.gz
通过 tar -xf 解压缩后,Prometheus 部署相关的 YAML 文件都在 manifests 目录里。
在安装 Prometheus 之前,需要做一些准备工作。
- 修改 prometheus-service.yaml、grafana-service.yaml。这两个文件定义了 Prometheus 和 Grafana 服务对象,可以给它们添加 type: NodePort,这样就可以直接通过节点的 IP 地址访问(当然也可以配置成 Ingress)。
prometheus-service.yaml:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.36.1
name: prometheus-k8s
namespace: monitoring
spec:
type: NodePort
ports:
- name: web
port: 9090
targetPort: web
- name: reloader-web
port: 8080
targetPort: reloader-web
selector:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
sessionAffinity: ClientIP
grafana-service.yaml:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 8.5.5
name: grafana
namespace: monitoring
spec:
type: NodePort
ports:
- name: http
port: 3000
targetPort: http
selector:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
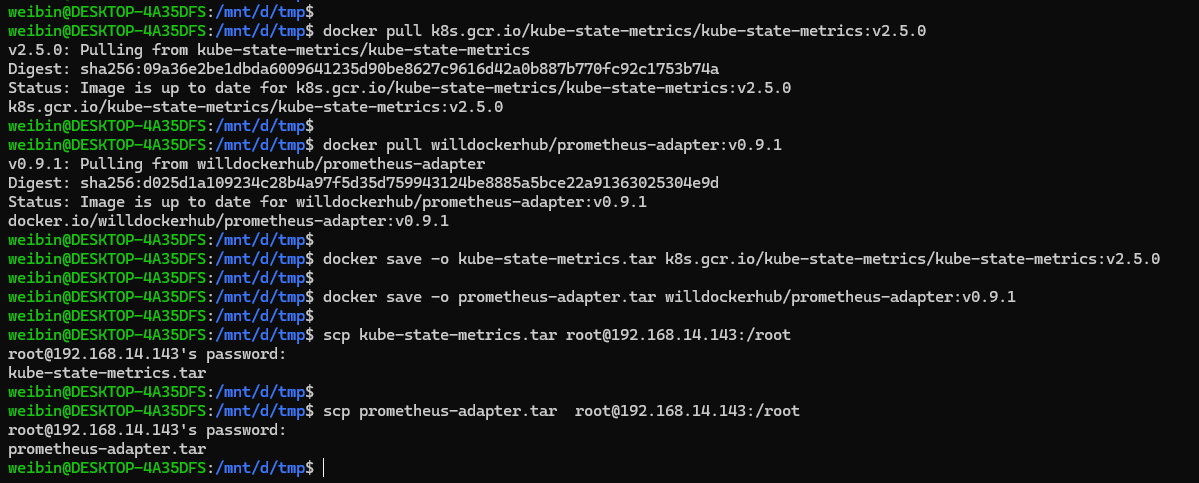
- 解决 kubeStateMetrics-deployment.yaml、prometheusAdapter-deployment.yaml 的镜像下载问题,因为它们里面有两个存放在 gcr.io 的镜像。通过可以科学上网方式解决,或者把镜像下载到本地,通过 docker save,docker load 方式把镜像上传到节点机器上。
将 prometheusAdapter-deployment.yaml 中的镜像从 k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1 改成 willdockerhub/prometheus-adapter:v0.9.1
image: k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.5.0
image: willdockerhub/prometheus-adapter:v0.9.1
在准备工作完成后,可以执行两个 kubectl create 命令来部署 Prometheus,先是 manifests/setup 目录,创建名字空间等基本对象,然后是 manifests 目录:
kubectl create -f manifests/setup
kubectl create -f manifests
Prometheus 的对象都在名字空间 “monitoring” 里,创建之后可以用 kubectl get 来查看状态:
kubectl get pod -n monitoring
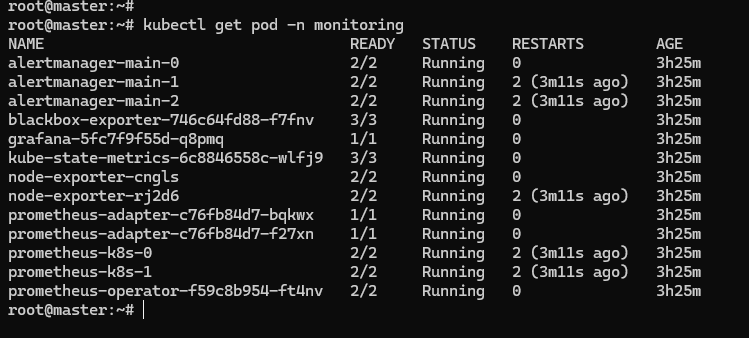
确定 Pod 都运行正常,再看看它对外的服务端口:
kubectl get svc -n monitoring
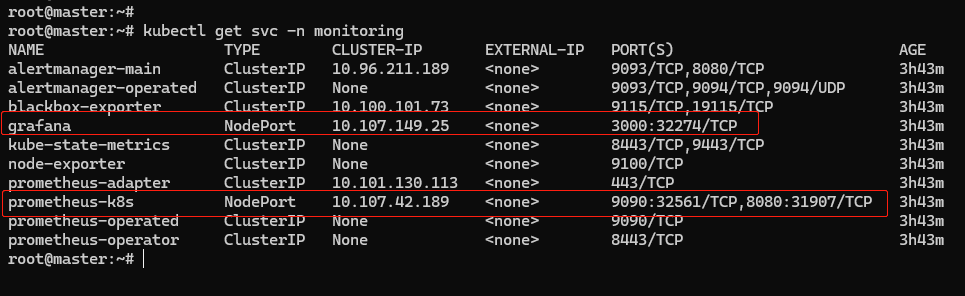
由于修改了 Grafana 和 Prometheus 的 Service 对象,所以这两个服务就在节点上开了端口,由上截图可知,Grafana 是 32274,Prometheus 有两个端口,其中 9090 对应的 32561 是 Web 端口。
在浏览器里输入节点的 IP 地址(任何一个节点的 IP 都可以),再加上端口号 32561,就能看到 Prometheus 自带的 Web 界面:
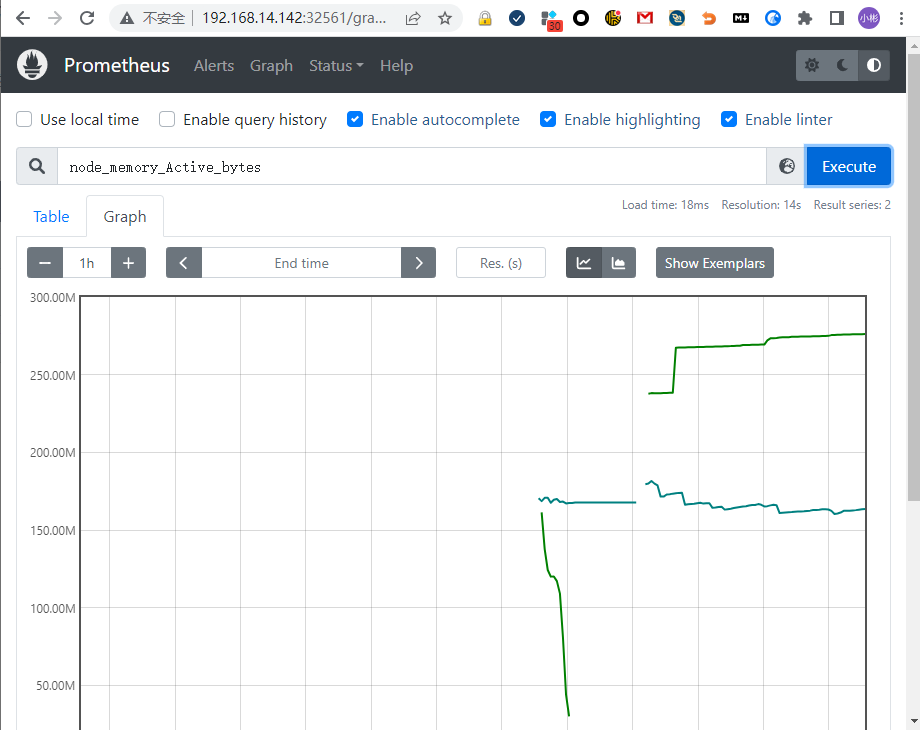
Web 界面上有一个查询框,可以使用 PromQL 来查询指标,生成可视化图表,以上截图选择了 “node_memory_Active_bytes” 这个指标,表示当前正在使用的内存容量。Prometheus 的 Web 界面比较简单,通常只用来调试、测试,不适合实际监控。
Grafana 访问节点的端口 32274,会要求先登录,默认的用户名和密码都是 admin:
Grafana 内部预置了很多强大易用的仪表盘,可以在左侧菜单栏的 “Dashboards - Browse” 里任意挑选一个:
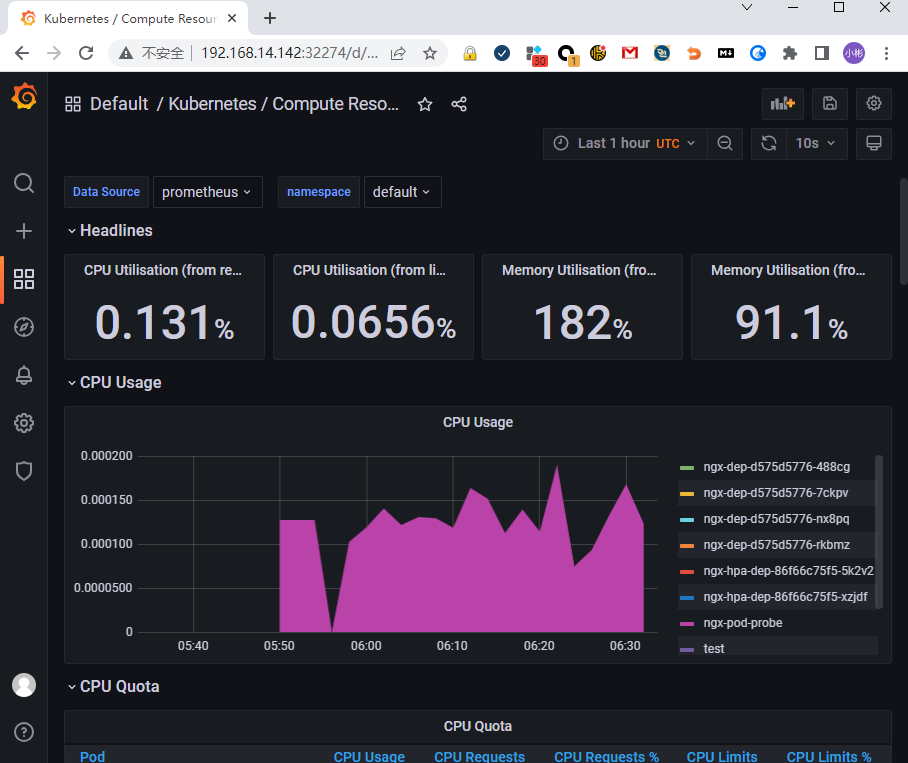
比如选择了 “Kubernetes / Compute Resources / Namespace (Pods)” 这个仪表盘,就会出来一个非常漂亮图表,比 Metrics Server 的 kubectl top 命令要好看得多,各种数据一目了然:
问题解决 #
我在部署时,执行 kubectl get pod -n monitoring 发现 alertmanager-main Pod 和 prometheus-k8s Pod 没有起来:
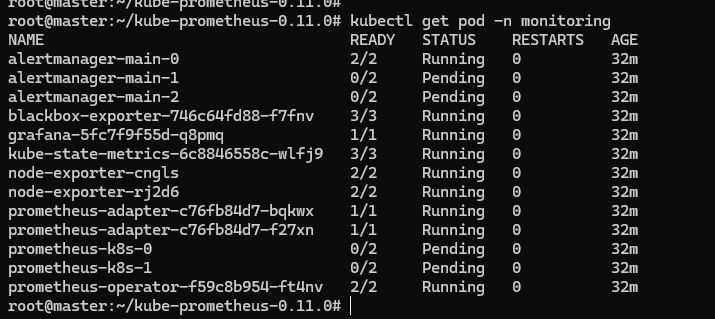
执行 describe 命令 kubectl describe pod prometheus-k8s-1 -n monitoring 发现有如下错误:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 33m default-scheduler 0/2 nodes are available: 1 Insufficient memory, 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate.
Warning FailedScheduling 27m (x4 over 32m) default-scheduler 0/2 nodes are available: 1 Insufficient memory, 1 node(s) had taint {node-role.kubernetes.io/master: }, that the pod didn't tolerate.
这个错误大概率是由于集群中机器不够导致的,可以通过去除掉 master 上的 tolerate 污点,让 master 节点也参与调度:

去除 master 节点的污点后,Kubernetes 会自动调度,再次执行 kubectl get pod -n monitoring 命令会发现 Pod 已经都运行正常了:
2.19.4 小结 #
-
Metrics Server 是一个 Kubernetes 插件,能够收集系统的核心资源指标,相关的命令是 kubectl top。
-
Prometheus 是云原生监控领域的 “事实标准”,用 PromQL 语言来查询数据,配合 Grafana 可以展示直观的图形界面,方便监控。
-
HorizontalPodAutoscaler 实现了应用的自动水平伸缩功能,它从 Metrics Server 获取应用的运行指标,再实时调整 Pod 数量,可以很好地应对突发流量。