2.3 实体数据 #
2.3.1 MIME #
“多用途互联网邮件扩展”(Multipurpose Internet Mail Extensions),简称为 MIME。
HTTP 用 MIME 标准规范来标记 body 的数据类型,这就是 “MIME type”。MIME 把数据分成了八大类,每个大类下再细分出多个子类,形式是“type/subtype” 的字符串。
简单列举一下在 HTTP 里经常遇到的几个类别:
-
text:文本格式的可读数据,最熟悉的应该就是 text/html 了,表示超文本文档,此外还有纯文本 text/plain、样式表 text/css 等。
-
image:图像文件,有 image/gif、image/jpeg、image/png 等。audio/video:音频和视频数据,例如 audio/mpeg、video/mp4 等。
-
application:数据格式不固定,可能是文本也可能是二进制,必须由上层应用程序来解释。常见的有 application/json,application/javascript、application/pdf 等,另外,如果实在是不知道数据是什么类型,像刚才说的 “黑盒”,就会是 application/octet-stream,即不透明的二进制数据。
HTTP 在传输时为了节约带宽,有时候还会压缩数据,为了不要让浏览器 “猜”,还需要有一个 “Encoding type”,告诉数据是用的什么编码格式,这样对方才能正确解压缩,还原出原始的数据。比起 MIME type 来说,Encoding type 就少了很多,常用的只有下面三种:
-
gzip:GNU zip 压缩格式,也是互联网上最流行的压缩格式;
-
deflate:zlib(deflate)压缩格式,流行程度仅次于 gzip;
-
br:一种专门为 HTTP 优化的新压缩算法(Brotli)。
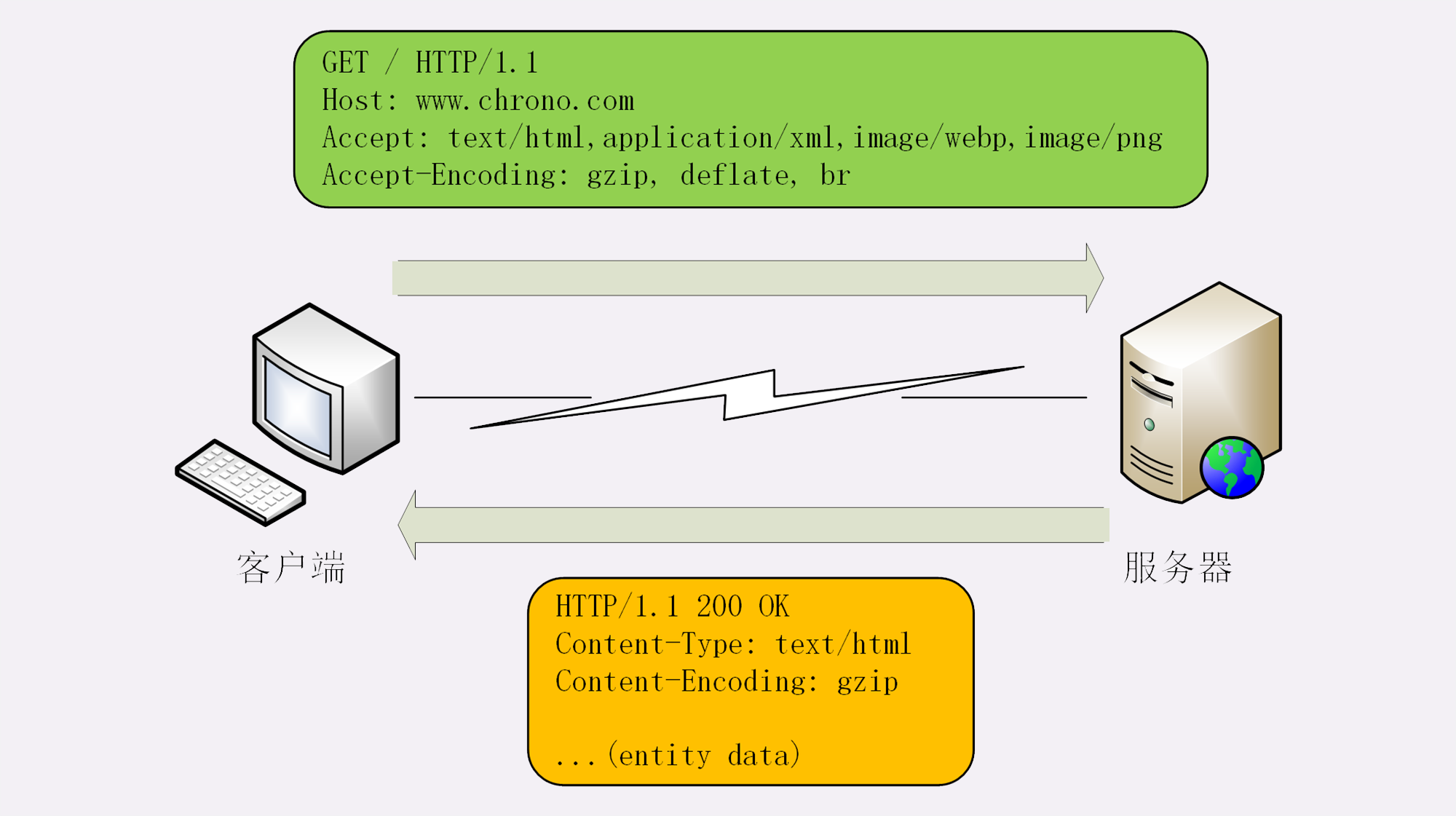
Accept 字段标记的是客户端可理解的 MIME type,可以用 “,” 做分隔符列出多个类型,让服务器有更多的选择余地,例如下面的这个头:
Accept: text/html,application/xml,image/webp,image/png
这就是告诉服务器:“我能够看懂 HTML、XML 的文本,还有 webp 和 png 的图片,请给我这四类格式的数据”。相应的,服务器会在响应报文里用头字段 Content-Type 告诉实体数据的真实类型:
Content-Type: text/html
Content-Type: image/png
这样浏览器看到报文里的类型是 “text/html” 就知道是 HTML 文件,会调用排版引擎渲染出页面,看到 “image/png” 就知道是一个 PNG 文件,就会在页面上显示出图像。
Accept-Encoding 字段标记的是客户端支持的压缩格式,例如上面说的 gzip、deflate 等,同样也可以用 “,” 列出多个,服务器可以选择其中一种来压缩数据,实际使用的压缩格式放在响应头字段 Content-Encoding 里。
Accept-Encoding: gzip, deflate, br
Content-Encoding: gzip
不过这两个字段是可以省略的,如果请求报文里没有 Accept-Encoding 字段,就表示客户端不支持压缩数据;如果响应报文里没有 Content-Encoding 字段,就表示响应数据没有被压缩。
2.3.2 编码 #
在计算机发展的早期,各个国家和地区的人们 “各自为政”,发明了许多字符编码方式来处理文字,比如英语世界用的 ASCII、汉语世界用的 GBK、BIG5,日语世界用的 Shift_JIS 等。
同样的一段文字,用一种编码显示正常,换另一种编码后可能就会变得一团糟。所以后来就出现了 Unicode 和 UTF-8,把世界上所有的语言都容纳在一种编码方案里,遵循 UTF-8 字符编码方式的 Unicode 字符集也成为了互联网上的标准字符集。