Docker 单机安装使用 Elasticsearch
1 安装 ES
当前 ElasticSearch 已经到了 8.0+,新版本都有很多新特性,性能和功能都有大幅提升,建议使用较高版本,这里采用 7.12.1 版本 👼

安装 ElasticSearch 脚本如下:
docker run -d \
--name elasticsearch \
-e "discovery.type=single-node" \
--privileged \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1常用命令说明:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定elasticsearch的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定elasticsearch的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定elasticsearch的插件目录--privileged:授予逻辑卷访问权-p 9200:9200:端口映射配置
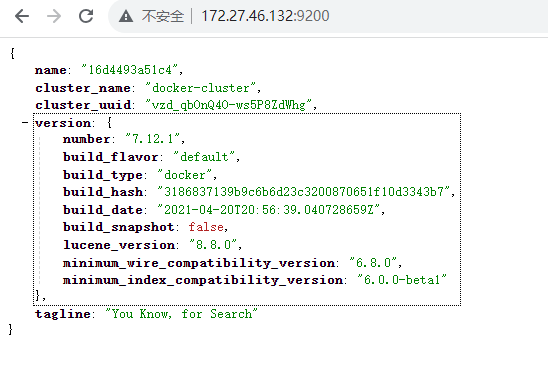
安装完成后,在浏览器中输入:http://172.27.46.132/:9200/ 即可看到 elasticsearch 的响应结果:
2 Kibana
我们可以基于 http 请求操作 ElasticSearch,但基于 http 操作比较麻烦,可以采用 Kibana 实现可视化操作。
Kibana 是一个免费且开放的用户界面,能够对 Elasticsearch 数据进行可视化,并在 Elastic Stack 中进行导航,可以进行各种操作,从跟踪查询负载,到理解请求如何流经的整个应用,都能轻松完成。Kibana 让能够自由地选择如何呈现自己的数据。
2.1 Kibana 安装
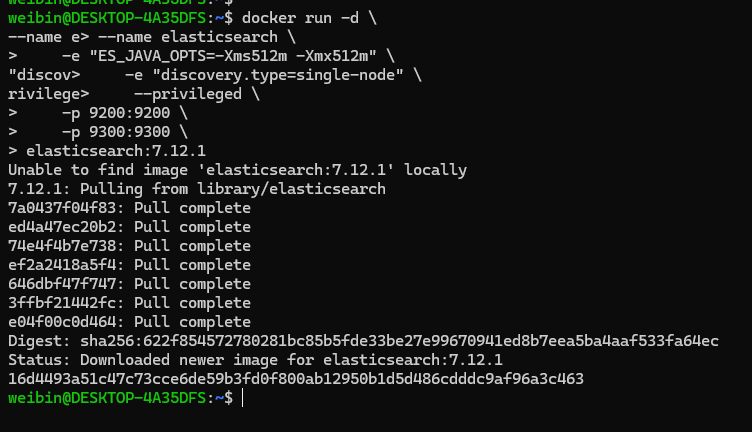
使用 Docker 安装 Kibana 非常简单,但是执行命令需要注意 Kibana 操作的 ElasticSearch 地址,因为 Kibana 是需要连接 ElasticSearch 进行操作的,所以需要 es 和 Kibana 在同一网段,安装 Kibana 命令如下:
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://172.27.46.132:9200 \
-p 5601:5601 \
kibana:7.12.1命令说明:
-e ELASTICSEARCH_HOSTS=http://172.27.46.132:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch,也可以写 IP 地址实现访问。-p 5601:5601:端口映射配置
安装的时候如果没有镜像,会下载镜像,效果如下:
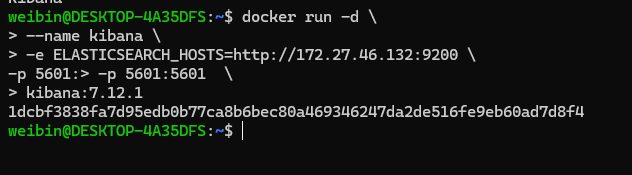
安装成功后,可以访问 http://172.27.46.132:5601/ 效果如下:
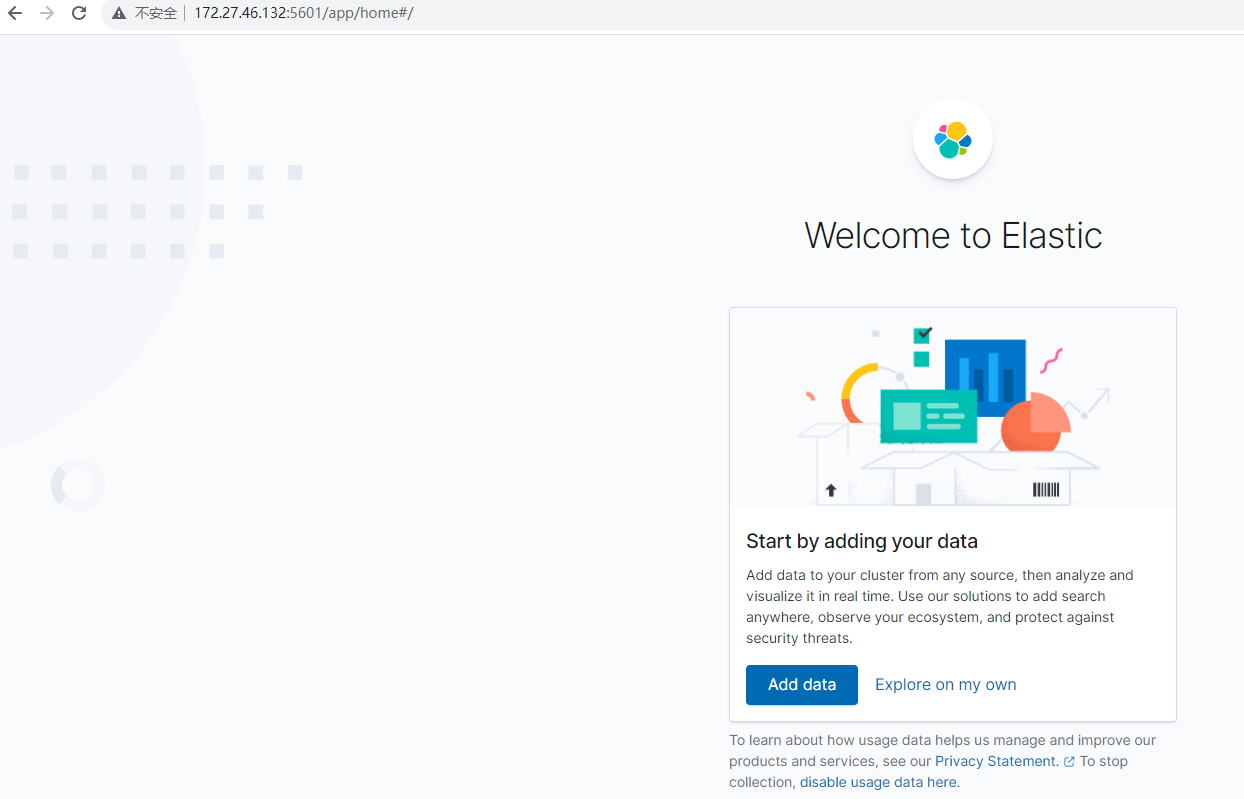
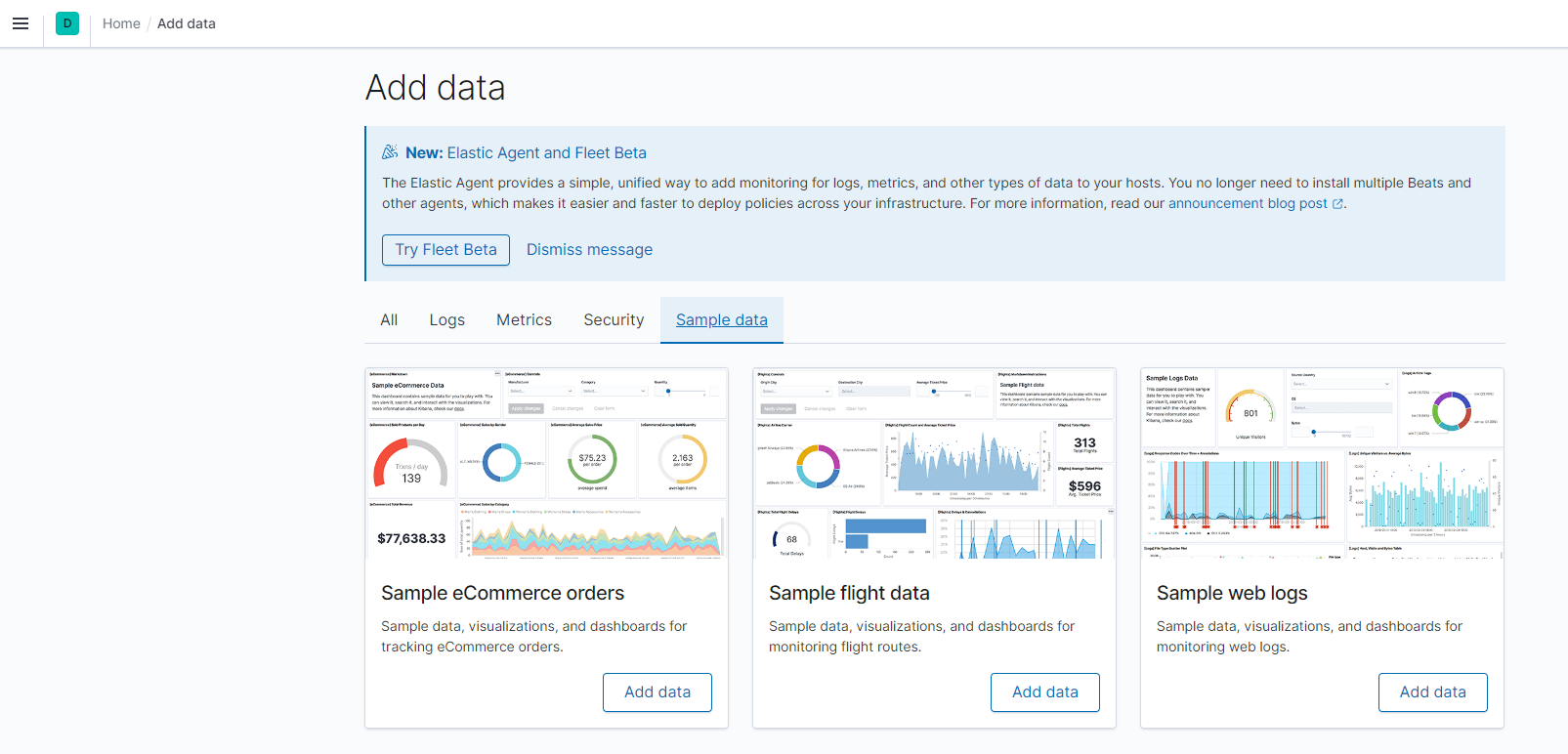
可以点击 Add data,添加示例数据,如下图,随意选一个即可,不选其实也是可以的。
2.2 Kibana 中文配置
Kibana 支持中文配置,可以把 Kibana 配置成中文版,切换中文操作如下:
#进入容器
docker exec -it kibana /bin/bash
#进入配置文件目录
cd /usr/share/kibana/config
#编辑文件kibana.yml
vi kibana.yml
#在最后一行添加如下配置
i18n.locale: zh-CN
#保存退出
exit
#并重启容器
docker restart kibana等待 Kibana 容器启动,再次访问 http://172.27.46.132:5601/ 效果如下:
3 IK 分词器安装
打开 Kibana,点击开发工具,操作如下:
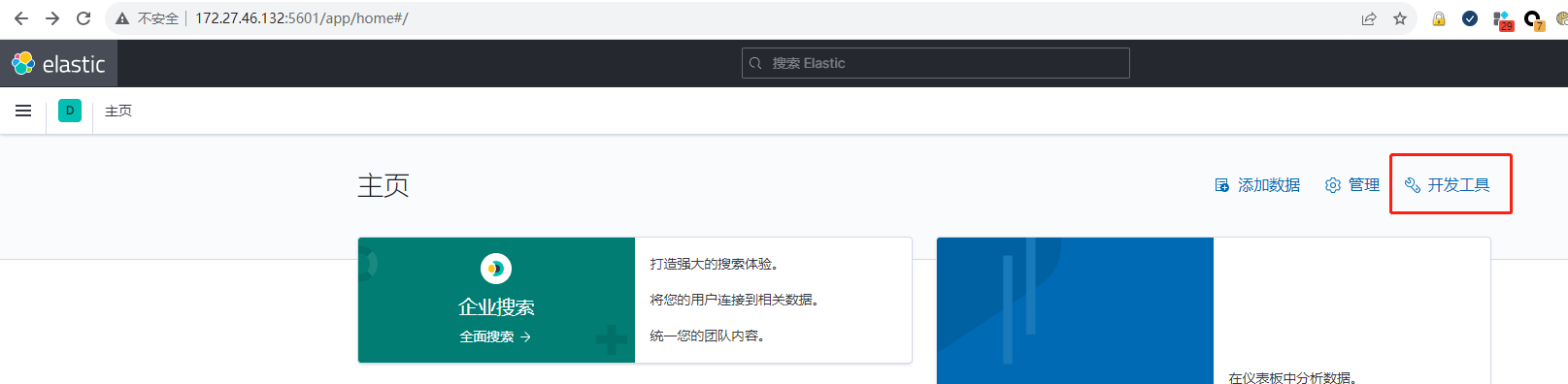
在左边输入如下内容,用于查询分词:
GET _analyze
{
"analyzer": "standard",
"text": "php 是世界上最好的语言"
}效果如下:
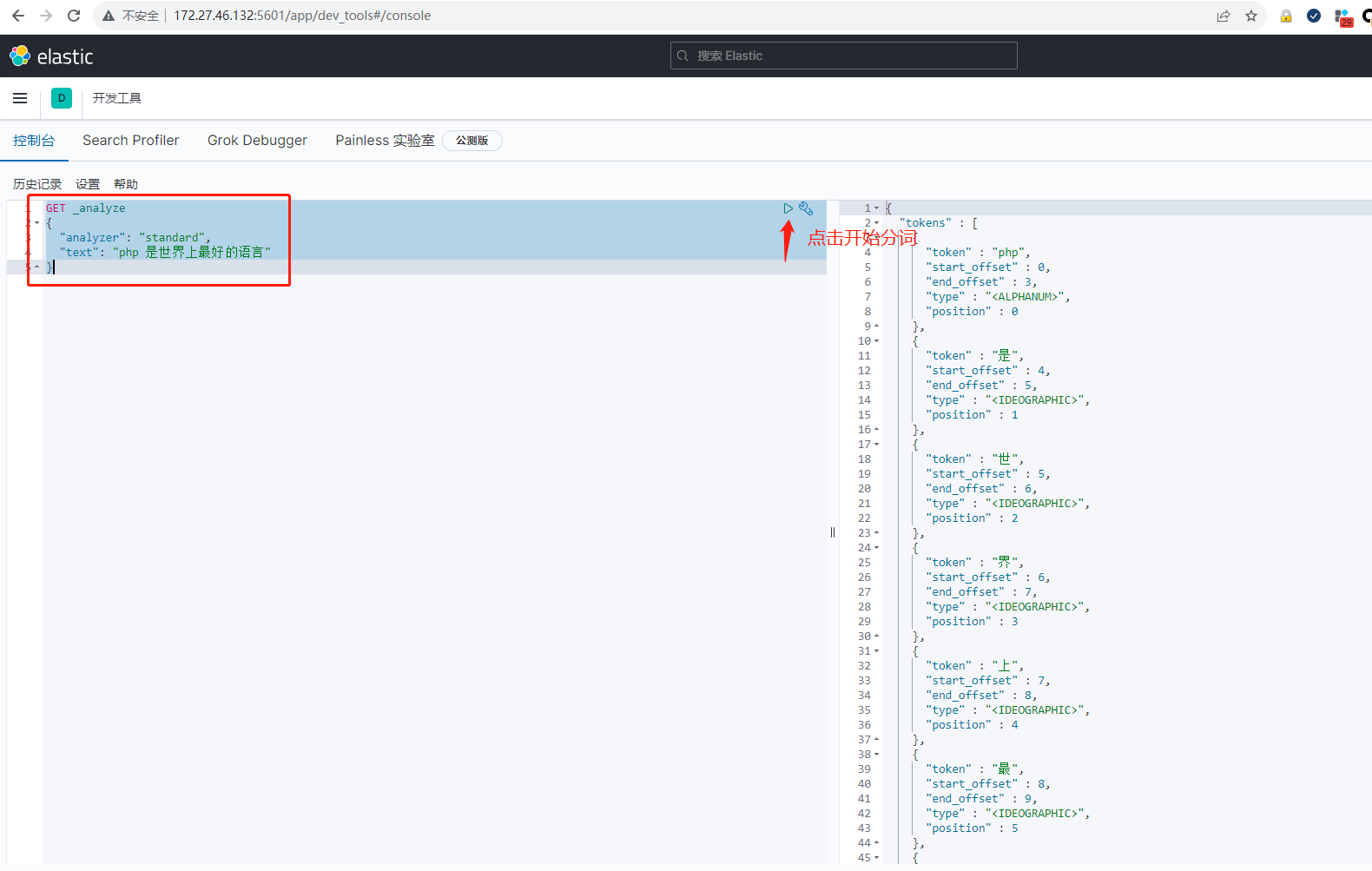
使用 standard 对 php 是世界上最好的语言 进行分词。
分词:提取一句话或者一篇文章中的词语。
我们在使用 ElasticSearch 的时候,默认用 standard 分词器,但 standard 分词器使用的是按空格分词,这种分词操作方法不符合中文分词标准,我们需要额外安装中文分词器。
3.1 IK 分词器
IK Analyzer 是一个开源的,基于 java 语言开发的轻量级的中文分词工具包。可以直接在 ElasticSearch 中集成 IK 分词器,IK 分词器集成ElasticSearch下载地址:elasticsearch-analysis-ik/releases。IK 可以跟 es 的版本一致,我们 es 的版本是 7.12.1,IK 的版本也是用 7.12.1。
3.2 IK 分词器配置
下载安装包 elasticsearch-analysis-ik/releases/tag/v7.12.1 后,,需要将 elasticsearch-analysis-ik-7.12.1.zip 拷贝到 elasticSearch 容器里的的 /usr/share/elasticsearch/plugins 目录中解压即可。
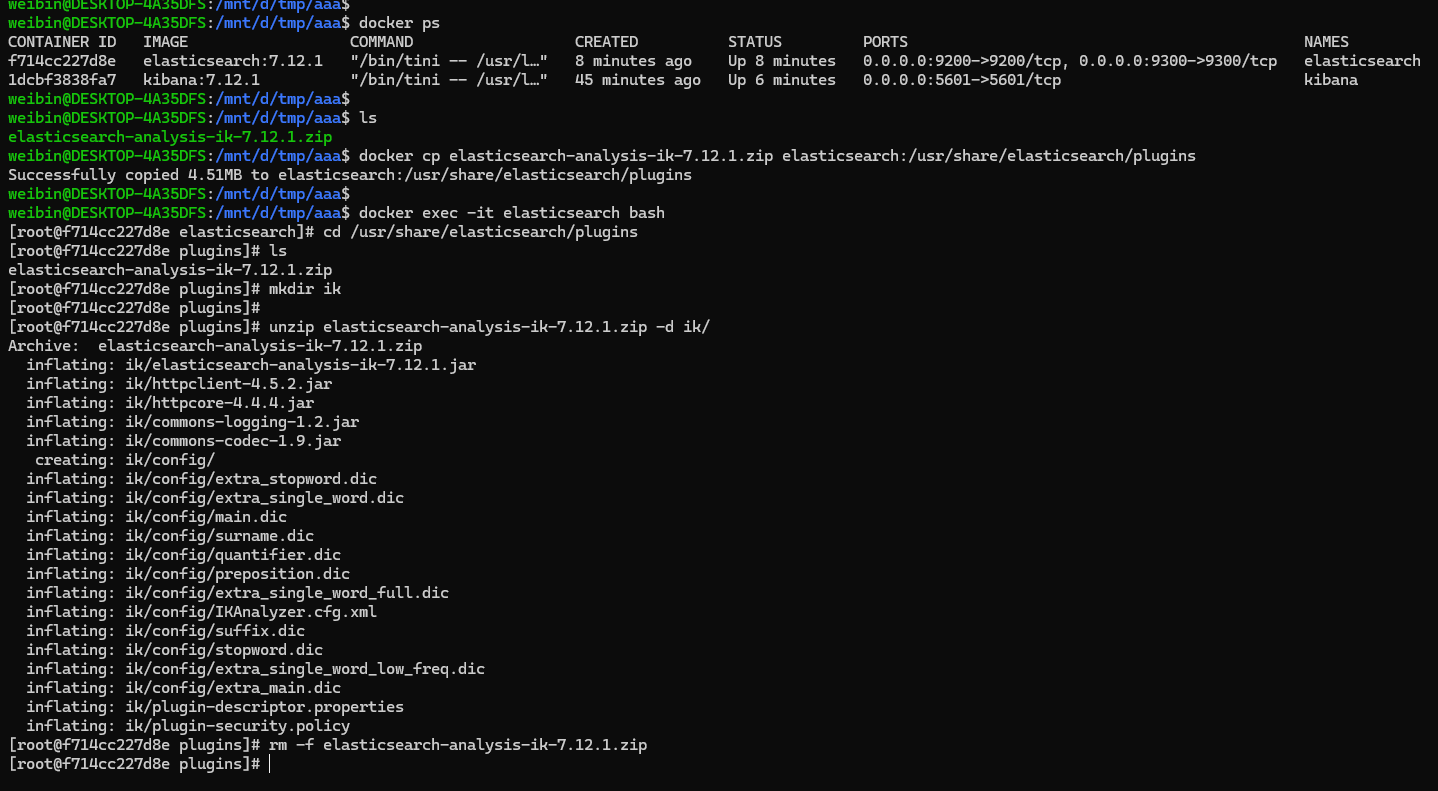
解压文件成功后,然后重启 es 容器。
3.3 分词测试
IK分词器包含两种模式:
-
ik_smart:最少切分 -
ik_max_word:最细切分
前面使用默认的standard分词器,对中文分词非常难用,安装IK分词器后,我们可以使用IK分词器测试,测试代码如下:
GET _analyze
{
"analyzer": "ik_max_word",
"text": "php 是世界上最好的语言"
}测试效果如下:
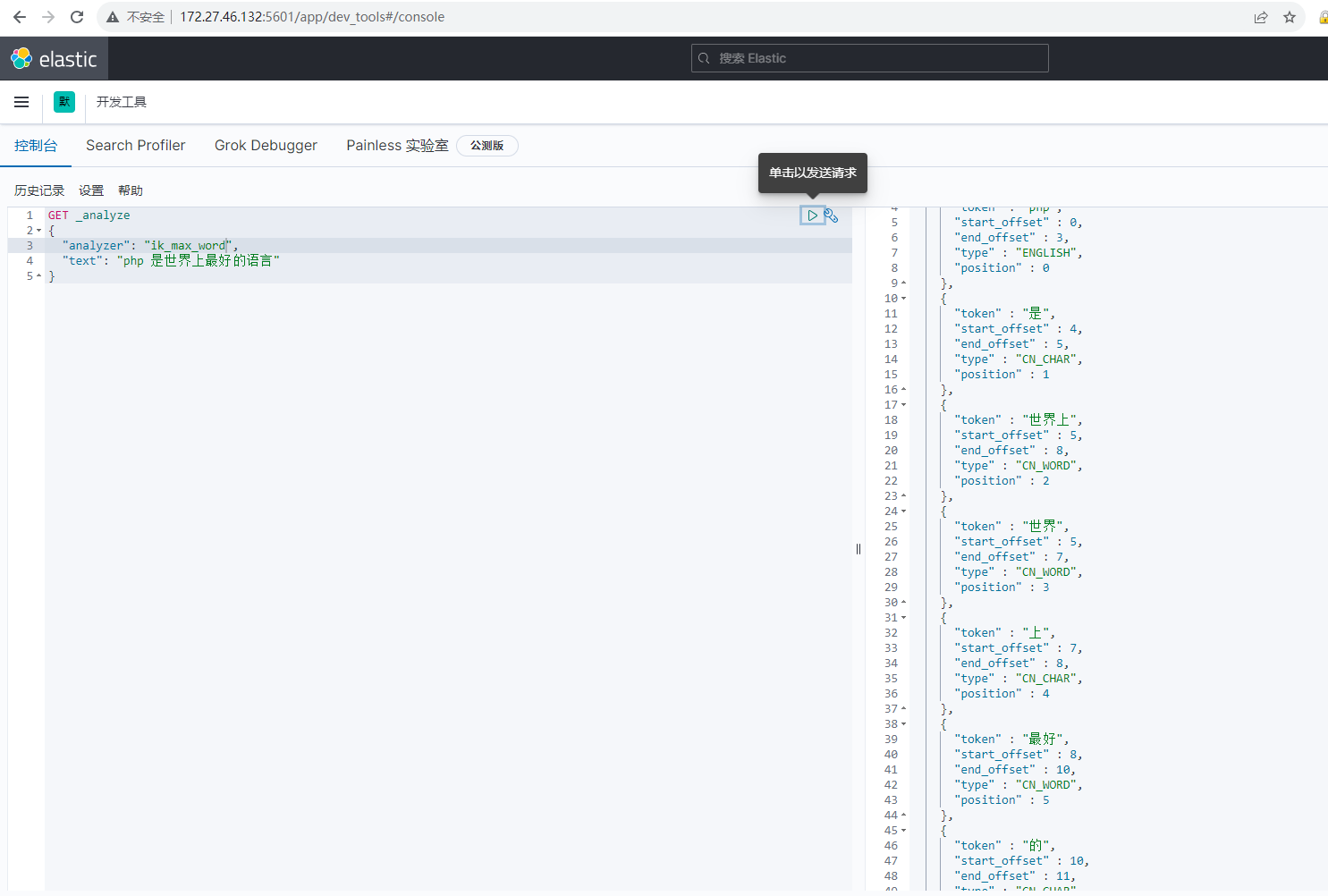
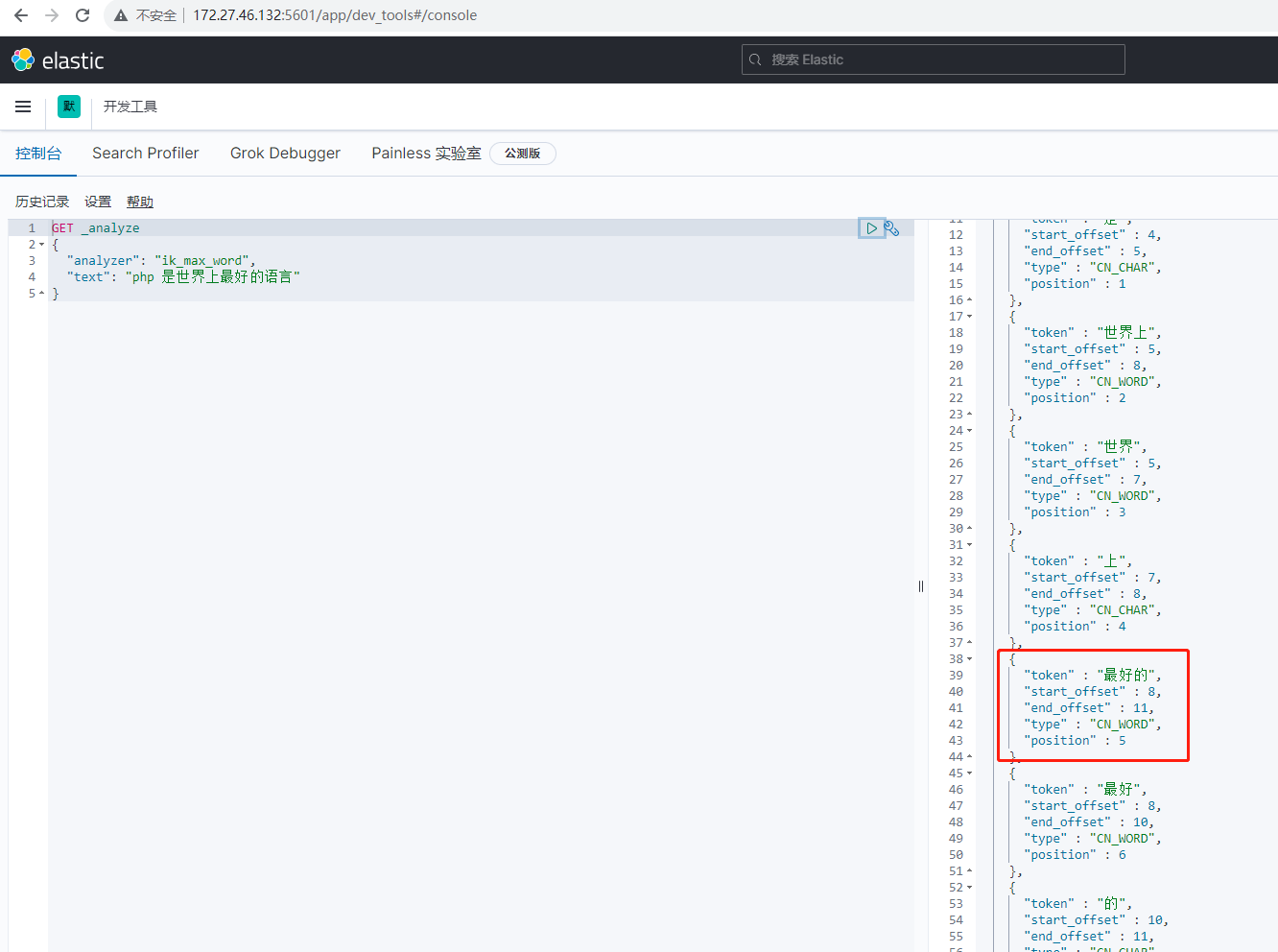
可以发现对中文的分词效果是比较不错的,但也存在一些不足,比如 最好的 我们希望它是一个词,而 上我们希望它不被识别一个词,这种需求可以同过自定义词典解决。
4 IK 自定义词典
IK 分词器支持自定义词典,包括自定义分词,也包含自定义停用分词,操作起来非常简单。接下来实现一下自定义词典和停用词典。
4.1 自定义词典
自定义词典,需要先创建自己的词典,再引用自己的词典即可。
- 创建词典
在 es 容器目录 /usr/share/elasticsearch/plugins/ik/config 中创建自己的词典,例如叫 custome.dic,在文件中添加自定义的词语,操作如下:
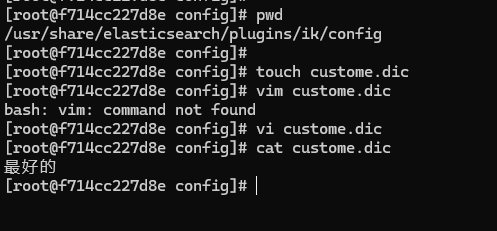
我们把自定义的词典 最好的 添加到了 custome.dic 中了,这就是创建词典,如果有多个自定义词,需要换行加入,这里一定要注意中文分词设置编码格式为 UTF-8。
- 引用词典
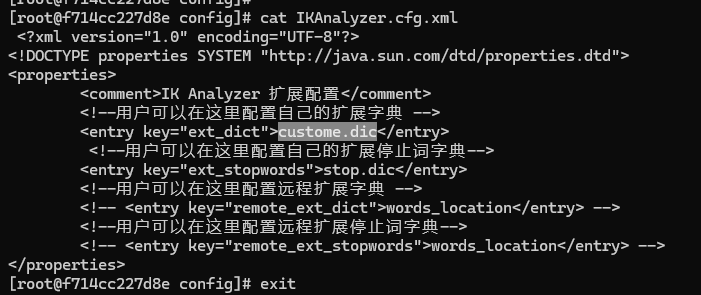
修改 config/IKAnalyzer.cfg.xml 引用自己创建的 custome.dic 词典,配置如下:
再使用 Kibana 效果如下:
4.2 自定义停用词汇
自定义停用词典和自定义词典一样,需要先创建自己的词典,再引用自己的词典即可。
- 创建词典
在 config 中创建自己的停用词典,例如叫 stop.dic,在文件中添加自定义的停用词语,操作如下:
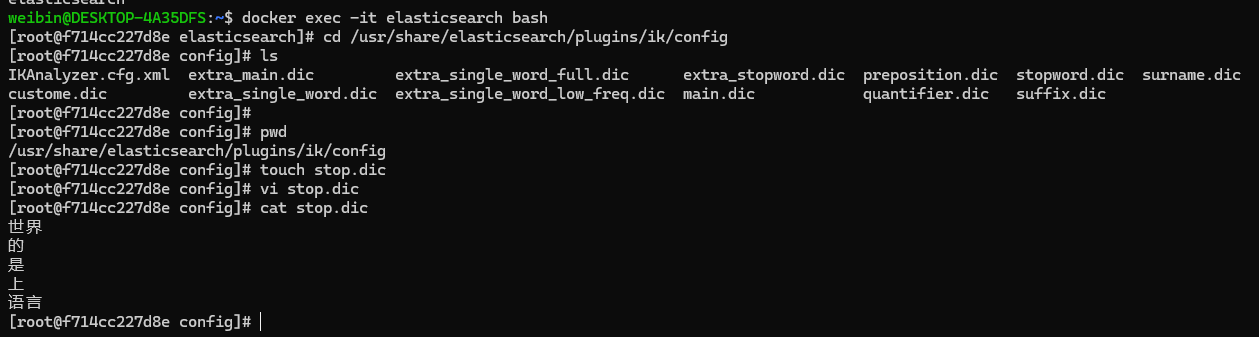
- 引用词典
修改 config/IKAnalyzer.cfg.xml 引用自己创建的 stop.dic 停用词典,配置如下:
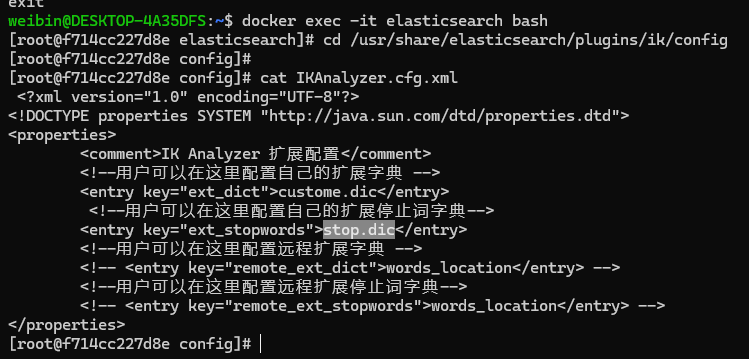
修改完成后,重启 elasticsearch 容器。
再使用 Kibana 测试效果如下:
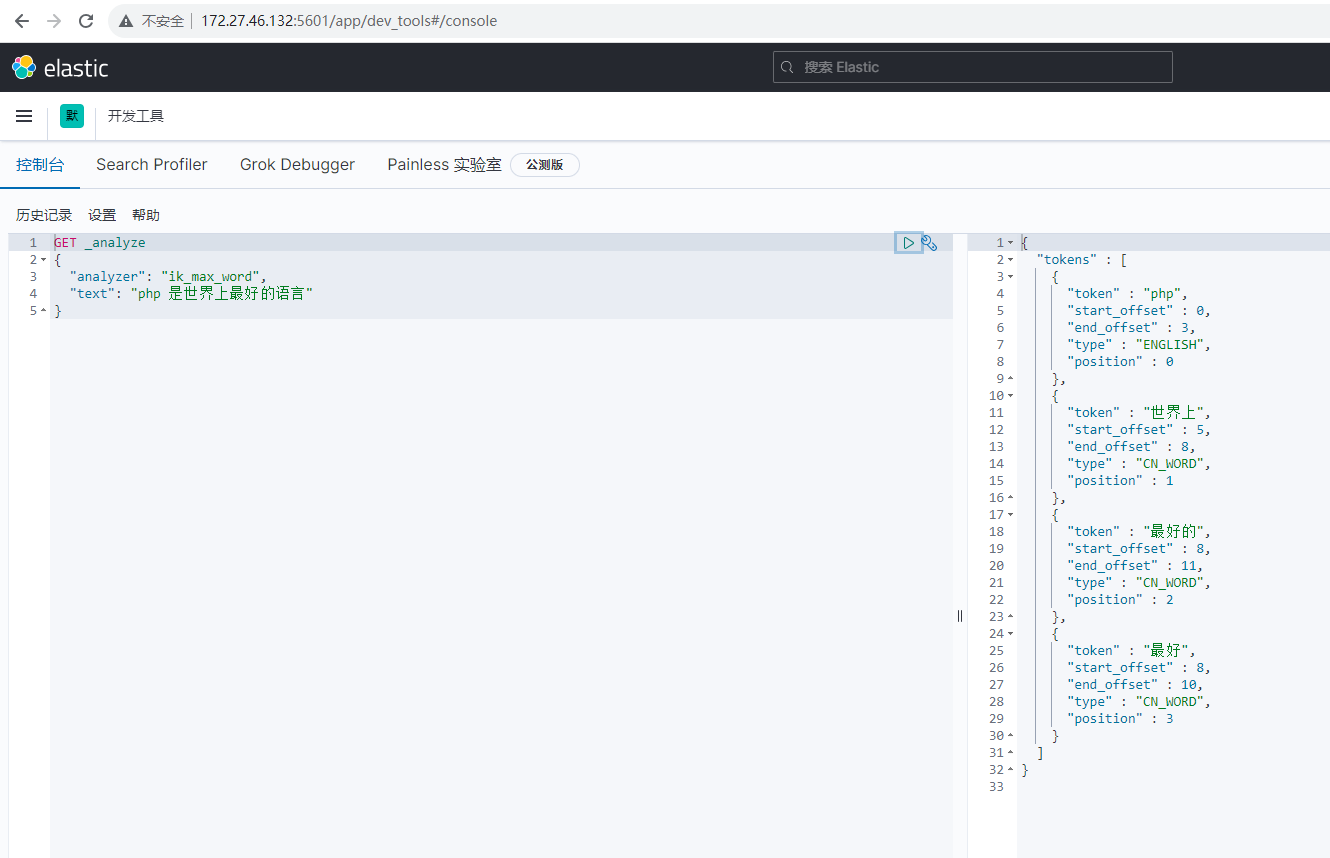
可以发现,不再有 世界,的,是,上,语言 的分词了,说明停用分词也生效了。
5 一个例子
现在有个需求是向 mysql 中插入文章,但是同时需要向 es 中写入文章,通过 es 来分词,优化搜索,通过 es 搜索时,可以返回 mysql 中对应的 id。
CREATE TABLE `article`
(
`id` int(10) unsigned NOT NULL AUTO_INCREMENT primary key,
`title` varchar(200) NOT NULL comment '文章标题',
`content` text COMMENT '文章内容',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文章表';golang 代码:
package main
import (
"context"
"database/sql"
"encoding/json"
"fmt"
"github.com/elastic/go-elasticsearch/v7/esapi"
_ "github.com/go-sql-driver/mysql"
"log"
"strings"
)
func main() {
// 初始化 MySQL 连接
db, err := sql.Open("mysql", "root:123456@tcp(localhost:3306)/wb-test")
if err != nil {
log.Fatal(err)
}
defer db.Close()
// 初始化 Elasticsearch 连接
esConfig := elasticsearch.Config{
Addresses: []string{"http://localhost:9200"},
}
esClient, err := elasticsearch.NewClient(esConfig)
if err != nil {
log.Fatal(err)
}
// 插入文章到 MySQL
articleTitle := "蝶恋花"
articleContent := "花褪残红注青杏小。燕子飞时,绿水人家绕。枝上柳绵注吹又少。天涯何处无芳草。墙里秋千墙外道。墙外行人,墙里佳人笑。笑渐不闻声渐悄。多情却被无情恼。"
_, err = db.Exec("INSERT INTO article (title, content) VALUES (?, ?)", articleTitle, articleContent)
if err != nil {
log.Fatal(err)
}
// 获取插入文章的 MySQL ID
var articleID int
err = db.QueryRow("SELECT LAST_INSERT_ID()").Scan(&articleID)
if err != nil {
log.Fatal(err)
}
// 在 Elasticsearch 中写入文章
esIndexName := "articles" // Elasticsearch 索引名
docID := fmt.Sprintf("%d", articleID)
//esDoc := map[string]interface{}{
// "title": articleTitle,
// "content": articleContent,
// "mysql_id": articleID, // 将 MySQL ID 存储在 Elasticsearch 中
//}
// 创建 Elasticsearch 文档
esRequest := esapi.IndexRequest{
Index: esIndexName,
DocumentID: docID,
Body: strings.NewReader(fmt.Sprintf(`{
"title": "%s",
"content": "%s",
"mysql_id": %d
}`, articleTitle, articleContent, articleID)),
Refresh: "true",
}
res, err := esRequest.Do(context.Background(), esClient)
if err != nil {
log.Fatal(err)
}
defer res.Body.Close()
// 从 Elasticsearch 中查询文章,包括 MySQL ID
//esQuery := map[string]interface{}{
// "query": map[string]interface{}{
// "match": map[string]interface{}{
// "title": "示例文章标题",
// },
// },
//}
esSearchRequest := esapi.SearchRequest{
Index: []string{esIndexName},
Body: strings.NewReader(fmt.Sprintf(`{
"query": {
"match": {
"title": "示例文章标题"
}
}
}`)),
}
res, err = esSearchRequest.Do(context.Background(), esClient)
if err != nil {
log.Fatal(err)
}
defer res.Body.Close()
// 处理 Elasticsearch 查询结果
if res.IsError() {
log.Fatalf("Error: %s", res.Status())
}
// 解析查询结果
var response map[string]interface{}
if err := json.NewDecoder(res.Body).Decode(&response); err != nil {
log.Fatalf("Error parsing the response body: %s", err)
}
hits := response["hits"].(map[string]interface{})["hits"].([]interface{})
for _, hit := range hits {
source := hit.(map[string]interface{})["_source"].(map[string]interface{})
title := source["title"].(string)
content := source["content"].(string)
mysqlID := source["mysql_id"].(float64) // 从 Elasticsearch 中获取 MySQL ID
fmt.Printf("标题: %s内容: %sMySQL ID: %d", title, content, int(mysqlID))
}
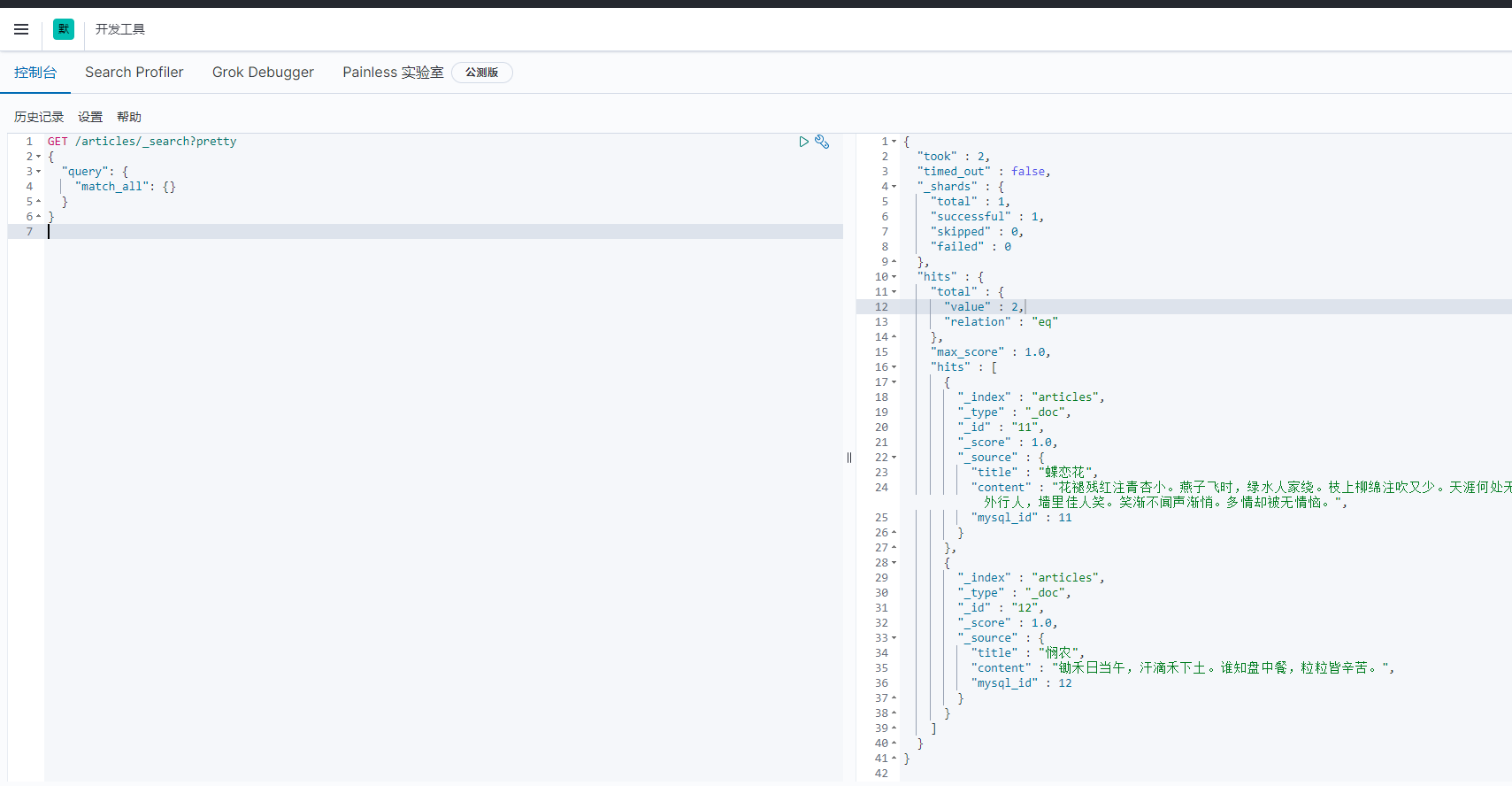
}通过 kibana 查看到 es 现在有 2 条数据:
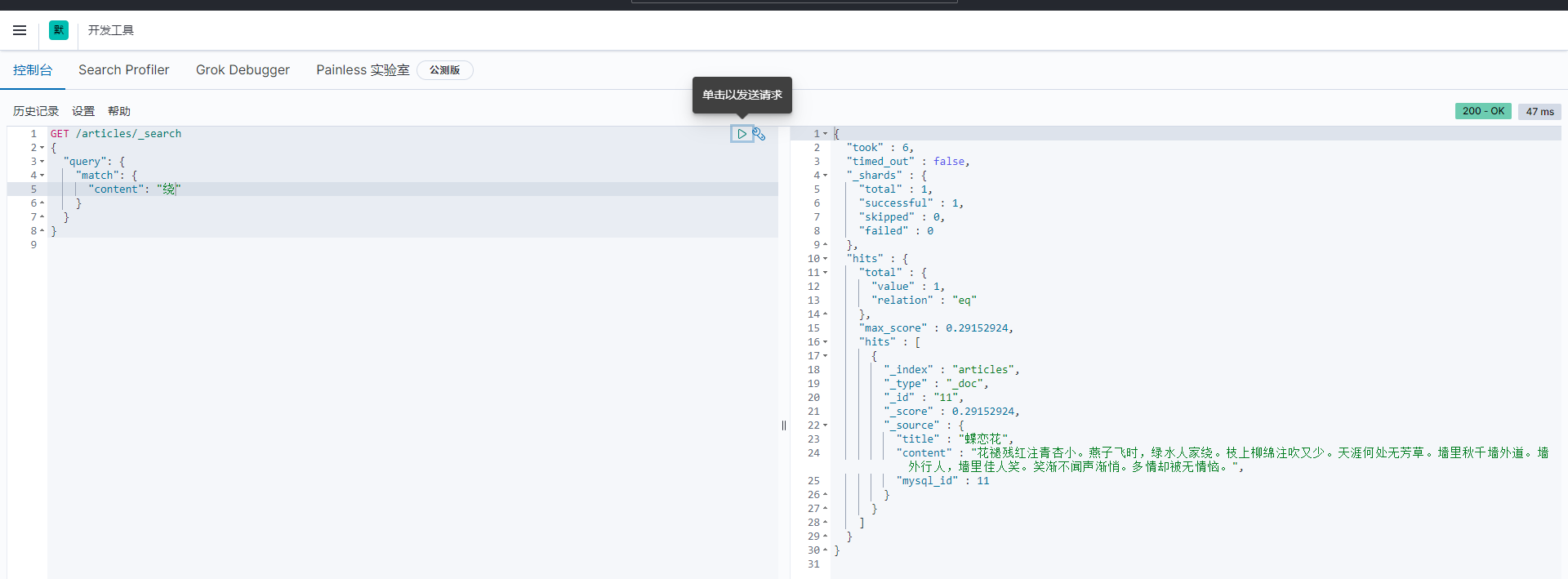
在 kibana 中通过查询接口搜索 content 内容包含 “绕” 的,展示效果如下:
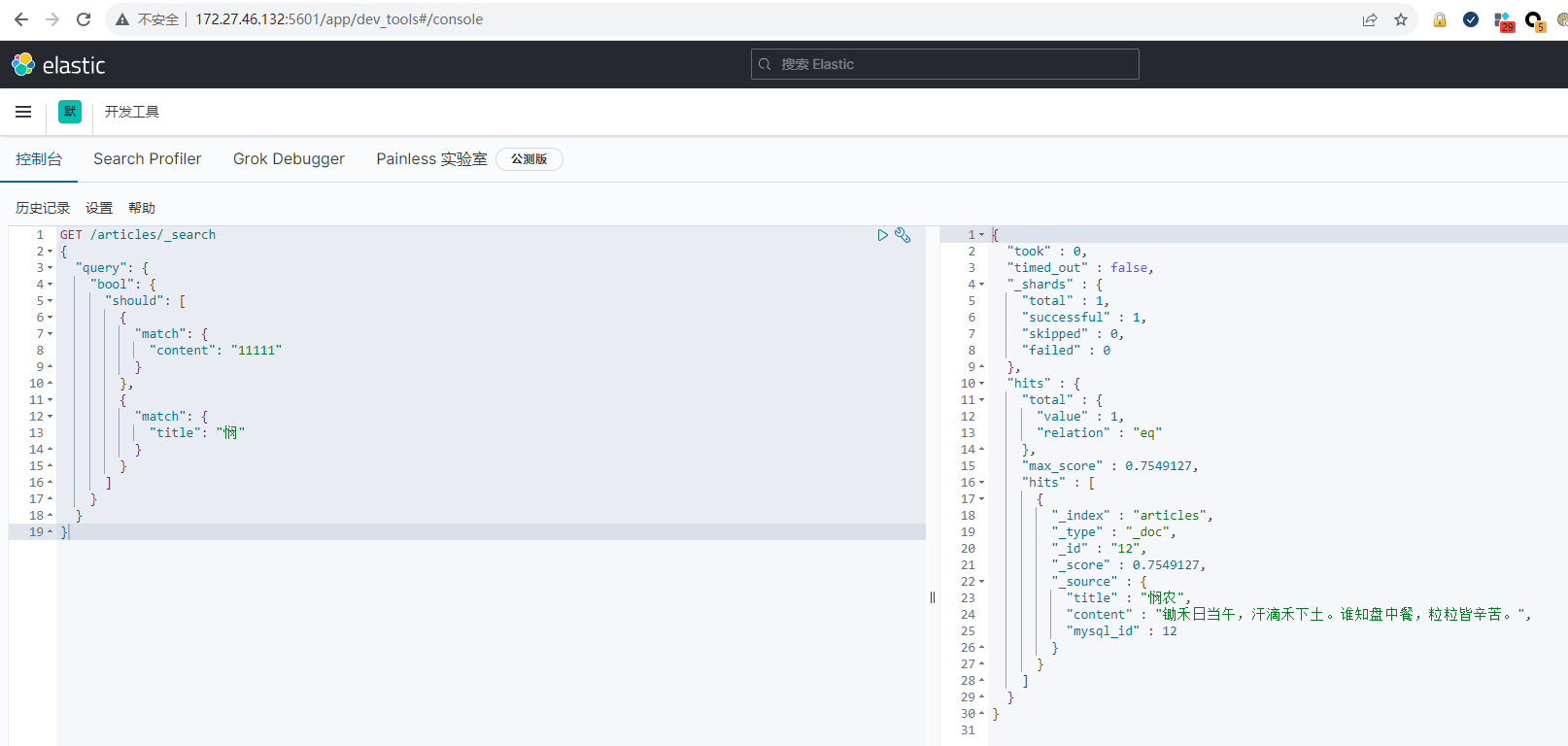
查询 content 含有 “11111” 或 title 中含有 “悯” 的数据结果如下: